반응형
내 맘대로 Introduction

이 논문은 MegaNeRF처럼 정해진 공간을 넘어서 광범위한 영역을 커버하는 방법 + 카메라 포즈를 SfM으로 초기화하지 않아도 학습할 수 있는 방법을 섞은 논문이다. 타겟을 video 영상으로 정하고 camera trajectory와 그 주변 공간을 여러개의 NeRF model로 나누어 SLAM처럼 같이 복원해나가는 논문이다.
핵심은 optical flow와 monodepth을 이용해 camera R|t 를 찾을 수 있도록 loss를 설계한 것과 현재 잡은 공간을 벗어나는 경우 벗어난 카메라를 중심으로 새로 공간을 잡아 업데이트 대상 공간을 갈아타는 것이다. 그리고 구현적으로도 메모리 이슈가 없도록 버릴 것 버리는 식으로 구현한 것도 의미가 있다.
메모하며 읽기
 |
|
 |
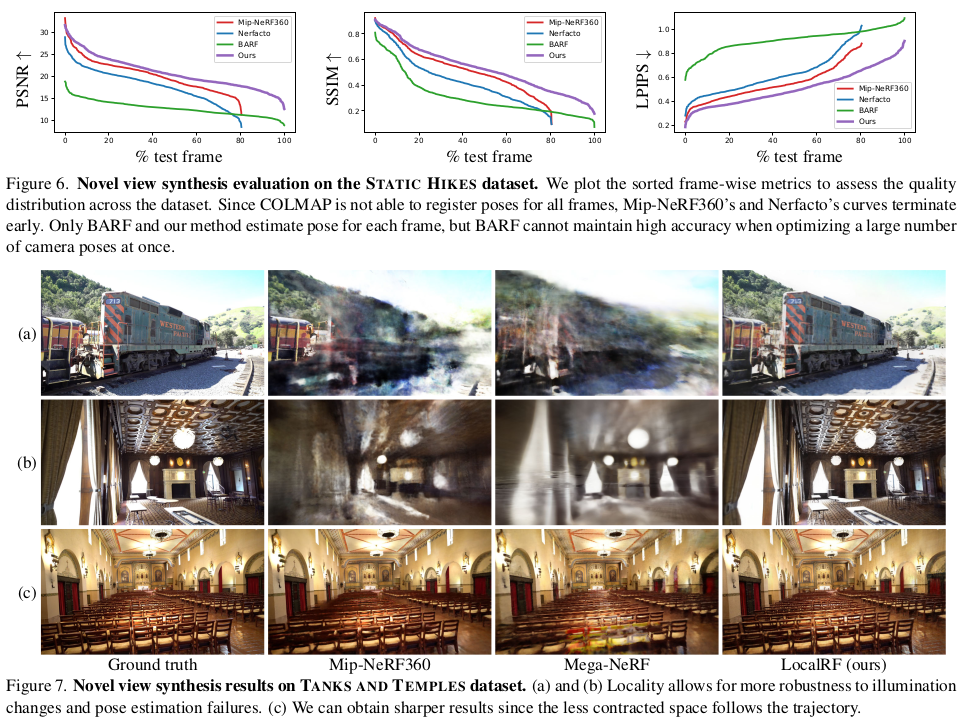
그림 한 방으로 설명이 가능한데 일단 TensoRF 표현법을 기본으로 하고 처음 공간을 잡고 학습을 시킨 뒤, 새로운 이미지가 들어올 때 가장 마지막 카메라 위치랑 동일하게 초기화한다. 그리고 나서 마지막 카메라의 R|t를 optical flow와 monodepth supervision을 이용해 같이 업데이트해주고 종료하는 것을 반복하는 것이다. 공간을 벗어날 경우 그림에서 녹색과 같이 새로 공간을 잡고 위 행위를 반복하는 식으로 점점 쌓아나가는 컨셉이다. (궁금증은 지금 앞으로 걸어나가는 카메라 모션이기 때문에 저 공간과 공간 사이 교집합이 효과를 발휘하는 일이 없을 것 같은데, 카메라가 일직선 모션이 아니라 곡선 모션을 하면 효과가 더 좋으려나?) |
   |
여긴 TensoRF의 recap이다. 기본 수식 (2-4)는 이미 알고 있을 수식. 주변 공간을 어떻게 잡을 것이냐를 고민할 때 그냥 10m면 10m 이렇게 잡을 수도 있지만 그렇게 하면 하늘이 10m 공간 안에 반영되어 색깔을 만들어야 하기 때문에 성능이 망가진다. 이를 해결하기 위한 방법이 Mip-NeRF360에 있는데, 공간을 모두 고르게 사용하는 것이 아니라 1m를 넘어서는 공간은 수식(5)와 같이 점점 압축된 상태로 표현되도록 모델링해서 사용한다. 이렇게 하면 압축되어 있지만 먼거리를 포함하기 때문에 성능 저하가 적다. 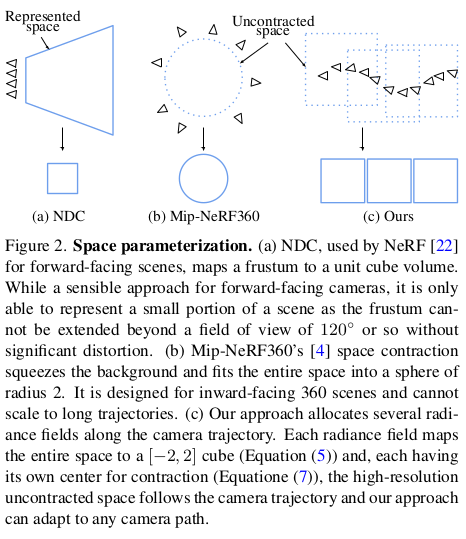 |
  |
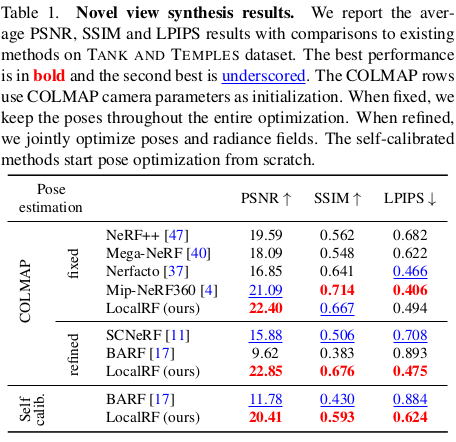
시작은 첫 공간을 5장 정도의 적은 프레임으로 먼저 복원하는 것으로 시작한다. 이 때는 self-calibrating nerf나 BARF 같이 정해진 공간 안에서 적은 수의 프레임일 때 잘 수렴하는 모델처럼 학습한 것 같다. 이후에는 마지막에 점점 추가되는 이미지에 대해서만 카메라 포즈를 trainable로 남겨두고 color, opacity와 함께 업데이트해주는 식이다.  이러한 방식이 그냥 통째로 돌렸을 때보다 성능과 안정성이 더 뛰어나다고 한다. (공간 잡는 문제는 둘째치고) |
  |
 계속 쌓아나가는 방식의 우수성을 설명하는 것인데, 통째로 쌓으려고 노력한다면 (1) outlier 카메라가 껴있을 때 전체가 망가지는 단점이 있고, (2) 애초에 모델하나가 그렇게 광범위한 영역을 복원할 능력이 없다는 단점이 있다. 이를 해결하기 위해서 공간을 꼭 나눠야 한다고 한다. 처음 잡은 공간을 벗어나서 새로운 공간을 잡아야할 타이밍에 해줘야하는 일은 좌표계만 global하게 맞춰주면 그만이다. 새공간을 잡을 때 카메라 위치를 중점으로 공간 간의 회전은 없다고 가정하고 translation만 주고 새로만들기 때문에 좌표계 맞추는 것은 수식(7)과 같이 아주 간단하다. 새 공간으로 업데이트 대상을 옮길 때는 이전 공간은 freeze한다. |
  |
실제 사용한 loss는 RAFT를 이용하여 뽑은 optical flow, DPT를 이용해 뽑은 monodepth가 사용된다. 직관적으로만 보면, 카메라 포즈도 trainable일 때 현재 rendered depth와 optical flow 이용해 pixel을 다른 프레임으로 옮겼을 때 색상이 맞아떨어져야 한다는 논리다. rendered depth가 정확하도록 monodepth supervision은 당연히 추가되어 있다. depth normalization에 사용되는 mean, std는 단순히 median을 기반으로 생성했다. (정확하진 않을 것 같은데 잘 되나봄) |
 |
구현 디테일~ |
 |
|
 |
 |
 |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields (0) | 2023.10.25 |
|---|---|
| Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields (0) | 2023.10.24 |
| Neural Kernel Surface Reconstruction (0) | 2023.10.20 |
| Neural Fields as Learnable Kernels for 3D Reconstruction (0) | 2023.10.19 |
| Neural Splines: Fitting 3D Surfaces with Infinitely-Wide Neural Networks (0) | 2023.10.18 |