반응형
내 맘대로 Introduction

이 논문은 SIFT와 같은 가장 low level vision 기술인 image feature를 뽑는 네트워크를 소개한다. Superpoint와 같은 논문의 2022년 버전이라고 생각하면 되겠다. 기타 deep feature extraction 네트워크들은 detect-and-describe 즉 위치를 먼저 잡고 그 주위에 feature를 convolution함으로써 image feature화하는 방식을 많이 썼다. 하지만 이 논문은 반대로 describe-and-detect 순서로 변경한 것이 차이다.
먼저 descriptor가 잘 뽑히도록 한 뒤 위치를 잡기 때문에 descriptor가 좋아야 위치도 잘 잡히는 구조다. 따라서 descriptor가 더 까다롭게 학습되어 좋은 표현력을 갖추어야 된다는 것을 직관적으로 알 수 있다. 이러한 직관은 성능으로 이어진 것 같다. 네트워크 전체는 굉장히 간단하며 loss로 간단하다.
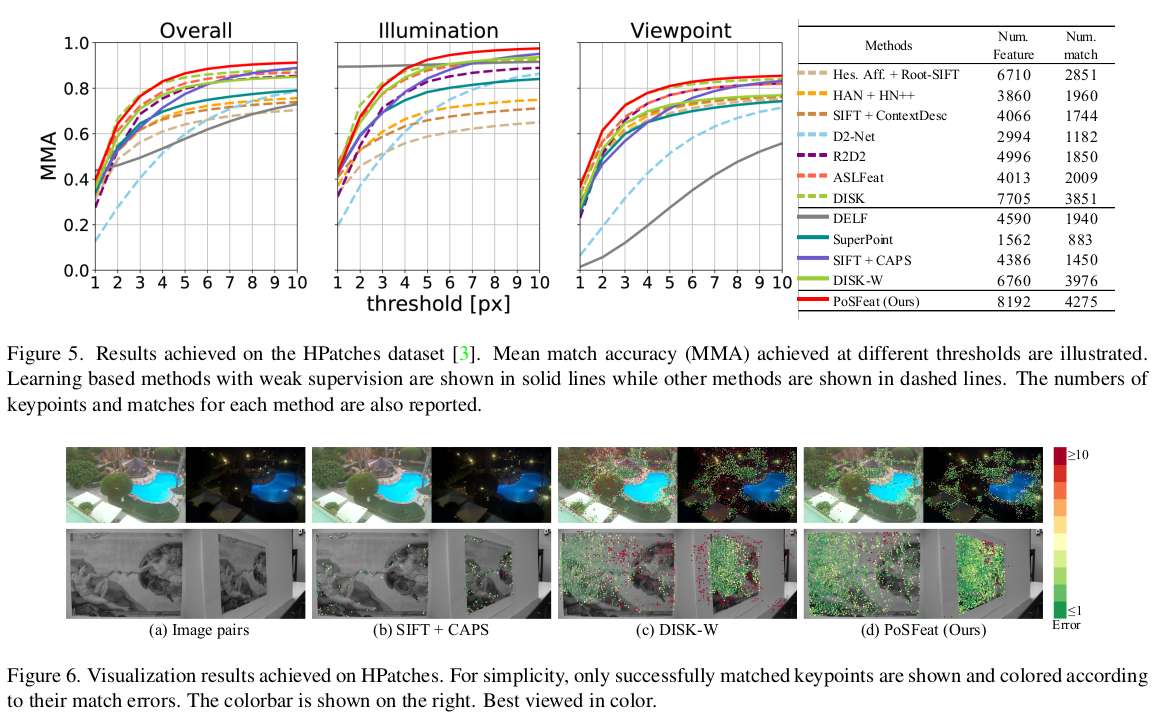
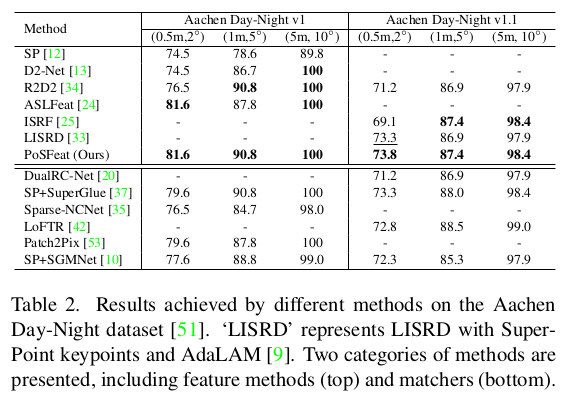
경험자의 말에 의하면 keypoint와 descriptor는 superpoint보다 좋다고 한다. descriptor를 갖고 brute-force하게 매칭을 해보면 PosFeat > Superpoint이다. 하지만 SuperGlue까지 붙여서 매칭까지 같이 보면 Superpoint + Superglue > PosFeat이라고 한다.
메모하며 읽기
 |
|
 |
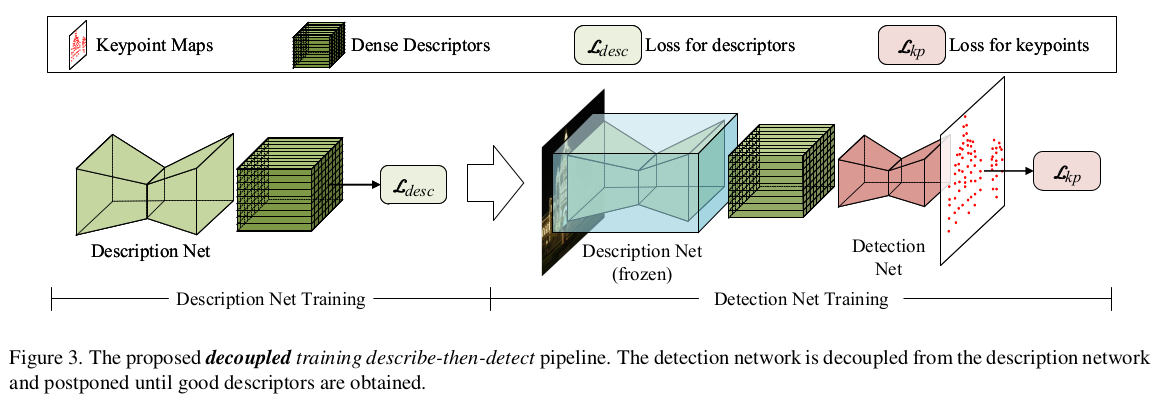
describe-and-detect 컨셉에 직관적으로 description net과 detection net이 연결된 구조로 되어있다. 두 네트워크를 같이 학습시키면 decoupling이 제대로 되지 않아 어느 네트워크의 능력으로 성능이 오르는지 분석이 안될 뿐만 아니라 중간 feature가 의도한대로 descriptor로 학습이 안될 수 있으므로 1) description net 먼저 학습시킨 뒤 freeze 2) detection net 추후 학습 방식으로 학습한다. |
 |
|
  |
descriptor net을 학습시킬 때 GT가 구하기 힘드므로 epipolar geometry를 이용한 weakly supervised 학습 방식을 택했다. (camera pose가 정확하다는 것을 믿는 방식) query 이미지에서 특정 위치마다 reference 이미지 상 비교 위치를 찾을 때 epiploar line 위에서만 선별한다. feature간 similarity를 softmax로 확률화하고 max인 위치를 매칭한다 좌측 그림 참고 |
 |
max operation을 하면 discrete pixel 단위로 찾게 되므로 이미지 해상도에 따라 성능이 다를 수 있다. 따라서 max로 찾은 위치 주변으로 patch를 펼쳐 최종 위치를 찾는다. patch 내 모든 픽셀과 query pixel 간 similarity를 계산하고 확률화한 다음 weighted sum하는 방식으로 continuous pixel 단위로 위치를 보정한다. |
 |
loss는 epiplar constraint를 이용한 1가지다. 1) reference point가 query epipolar line과 떨어진 거리가 0에가 까울 것 (epipolar geometry를 만족할 것) 이를 모든 query point에 대해서 mean을 취하는 방식이다. 이때 reference point가 variation이 큰 patch 출신이면 중요도가 낮아지고, variation이 낮은 patch 출신이면 중요도가 높아진다. |
  |
이제 descriptor net을 고정하고 detection을 할 차례다. descriptor map 전체를 받아 keypoint heatmap을 내뱉는 식으로 학습된다. 학습 방법은 query descriptor map, reference descriptor map을 뽑은 뒤, 각각 heatmap을 예측하도록 한다. 그다음 heatmap을 grid로 N x N grid화 한다음 grid cell 별로 1개 point를 생성한다. (grid cell 별로 softmax 취하고 weighted sum한 듯?) query candidates와 reference candidates 간 descriptor similiarty를 확률 Pm으로, query-reference candidate간 log(확률곱)으로 loss를 먹인다. 수식 (11)을 해석해보면, similiarty가 높을 경우, loss가 줄어들 방법은 query, reference cadidate가 keypoint일 확률이 1에 가까워야만 한다. 그래야 log==0이 될테니까. 반대로 simialirty가 낮을 경우, loss는 이미 0에 가까워지므로 keypoint일 확률은 기여하지 않는다. 이런식으로 similarity가 높은 keypoint들만 확률이 높도록 supervision이 계속 걸리는 식으로 학습된다. 전부 다 1로 수렴해버리면 어떡하냐는 질문에 답하기 위해 뒤에 regularization을 붙인 듯 하다. 더불어 eipolar constraint를 만족하면 가산점을 주기 위해 R을 추가하기도 했다. |
 |
|
  |
 |
 |
 |
반응형