반응형
내 맘대로 Introduction


제목에서 알 수 있다시피 Croco의 성능 개선편, v2다. 사실 상 엄청난 개선은 없고 성능을 끌어올리기 위한 기법들을 소개하는 것이다. 첫번째는 synthetic data만 썼던 v1 대비 large scale real data를 만든 것. 두번째는 모델 사이즈를 키운 것. 세번째는 rotary positional embedding으로 변경한 것이다. 그리고 downstream task로 binocular vision task에서 성능 향상이 얼마나 큰 지 강조하면서 geometric task에서의 우수성을 보여준다.
메모하며 읽기
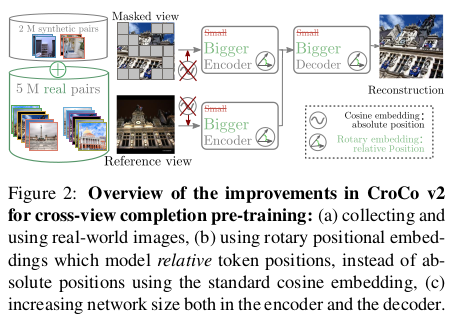 |
한 그림에 다 나와있다. 모델 크기 키웠고 실환경 데이터 무지막지하게 추가했고 positional embedding을 변경했다. |
  |
Croco v1 recap과 차이점을 간단 요약하는 것이다. 앞서 2번이나 이야기했으니 스킵. |
 |
|
  |
먼저 실환경 데이터셋을 모은 이야기다. 그냥 같은 장소면 마구잡이로 image pair를 형성하면 될 것 같지만 아니라고 한다. overlap이 일단 어느 정도 있어야 하는데 그렇다고 너무 많으면 네트워크가 그냥 copy-paste처럼 떼어오는 식으로 학습되어버릴 수도 있다고 한다. 그래서 overlap score base로 규칙을 생성하고 이를 기준으로 데이터를 생성했다고 한다. |
  |
overlap score는 이미지마다 어쨌든 camera pose와 SfM, Lidar mesh reconstruction 등으로 복원한 3D point가 있으니 point IoU로 계산했다. 즉, 두 이미지가 갖고 있는 3D point 총합 대비 둘 다 같이 갖고 있는 3D point 간의 비율을 계산한 것이다. ARKitScene 같은 경우는 mesh가 있으므로 occlusion 계산이 쉬워서 단순히 vertex를 세면 끝이고 MegaDepth같이 SfM으로 만들어진 데이터는 occlusion 계산이 안되므로 단순히 3D point마다 면을 갖는 구체를 할당해서 occlusion을 단순 계산하고 vertex를 셌다. 나머지 데이터셋도 같은 형태이며 NAVERLABS 데이터셋은 view frustrum으로 계산했다. |
 |
score를 갖고 이제 규칙은 어떻게 세우느냐. IoU가 일단 기본적으로 높아야 가치가 높은 데이터라는 것이 맞는데 이중 더 가치가 높은 것은 IoU가 높은데 view point 각도 차이 마저 큰 데이터다. 즉 같은 장소인데 시점 차이가 큰 것이 copy-paste를 방지하면서 좋은 학습을 유도할 수 있는 데이터다. 따라서 수식(2)과 같이 IoU와 시점 차이를 곱한 형태로 룰을 디자인했다. |
 |
|
  |
이렇게 만든 데이터는 224x224로 최종 crop해서 사용했다. 데이터량은 좌측 수치와 같다. |
 |
positional embedding은 기존 ViT가 쓰는 absolute positional embedding에서 rotary positional embedding으로 변경했다. RPE가 absolute + relative positional embedding 두 장점을 갖춘 방식이라서 이렇게 바꾼 것 같다. 이론적 기반보다 실험적인 기반으로 교체한 듯 |
  |
네트워크는 그냥 파라미터 수를 다 빵빵하게 늘렸다. v1에서 base를 썼다면 모두 large로 바꿨고 feature dimension과 head 개수 전부 다 늘렸다. 거의 1.3배 |
 |
|
 |
downstream task로 finetuning할 때는 DPT 모듈을 추가하는 것을 제안했다. Dense prediction transformer라는 구조로 ViT encoder + CNN decoder 조합에 가까운 구조라고 보면 된다. ViT encoder에서 중간중간 token 꺼낸 다음 image feature처럼 다시 concat 하고 CNN으로 feature를 뽑고 모아 CNN decoding하는 구조다. |
   |
구조가 핵심인 논문이니 loss나 학습 디테일은 중요하지 않으므로 생략. 그냥 구조를 이렇게 디자인하고 학습 잘 시키면 된다라는 뜻. |
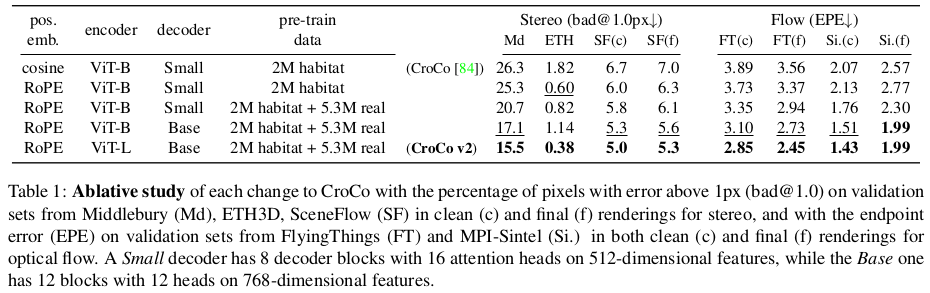 |
| 모델 크기 증가와 positional embedding 추가가 실제로 효과가 있었다. |
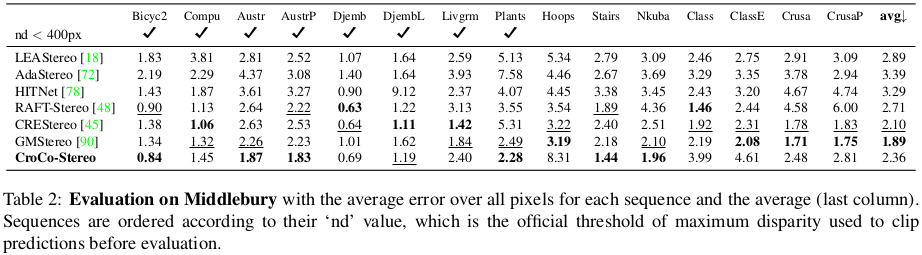 |
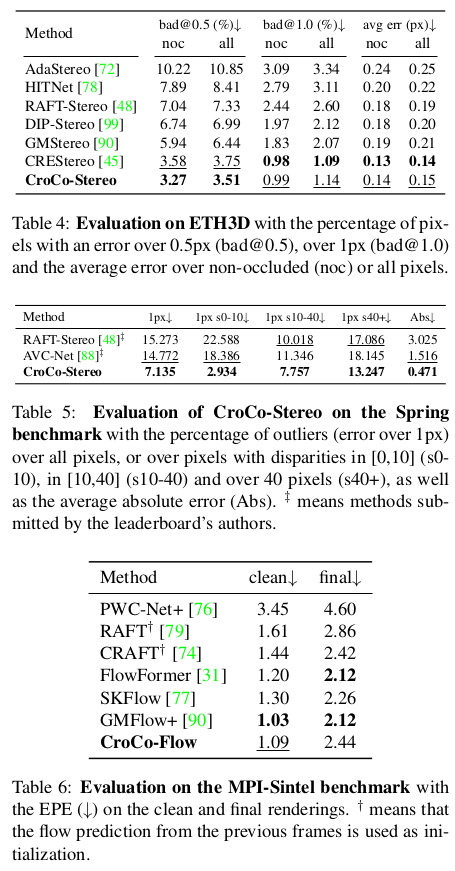
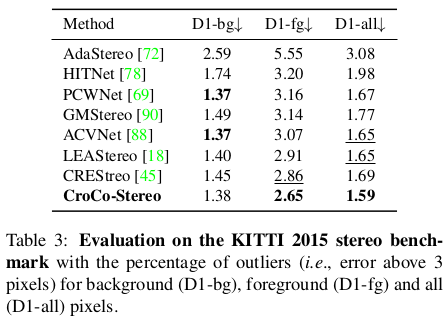
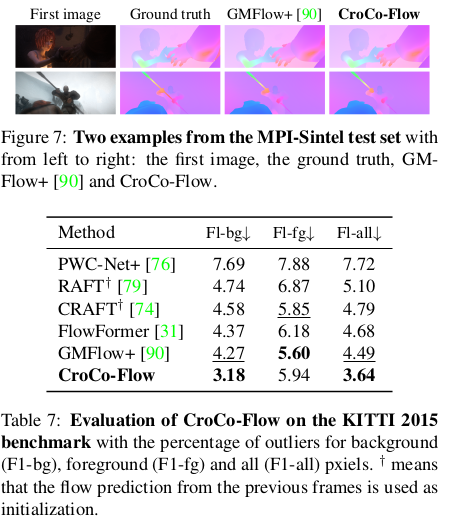
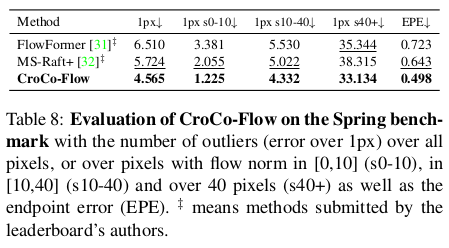
| pretrained backbone으로써 효과는 여전히 좋음 |
  |
   |
반응형