반응형
내 맘대로 Introduction
Dense prediction을 필요로 하는 task들은 (depth, semantic segmentation 등) encoder-decoder 구조를 많이 차용한다. 그리고 CNN으로 많이 구현한다. 하지만 메모리 사용량과 연산량 문제로 CNN encoder-decoder 구조는 downsampling을 많이 사용한다.
이 과정이 사실 많이 사용하고는 있으나 따지고 보면 dense prediction을 하기 위해 global context를 더 잘 보고 high frequency detail을 유지해야 하는 특성과 맞아 떨어지지는 않는다는 주장이다.

따라서 downsample이 포함되지 않는 ViT 구조를 encoder로 사용하고 CNN decoder를 조합하면 dense prediction task를 더 잘 풀 수 있는 encoder-decoder 구조가 된다는 논문이다.

메모하며 읽기
 |
|
   |
encoder는 그냥 ViT다. ViT 자체가 downsampling이 없는 구조이기 때문에 그냥 ViT를 encoder로 차용하면 끝. 뭐라뭐라 길게 써있는데 중요한 건 아니고 그냥 small, base, hybrid 세가지의 ViT 구조가 있다는 이야기고 각각의 디테일을 얘기할 뿐이다. hybrid는 image embedding 전 resnet50으로 image feature 뽑고 시작하는 방식. |
  |
decoder가 중요한데 decoder는 CNN이다. token to 2D feature로 재조합하는 과정이 여기서 말하는 reassemble 과정이다. 먼저 read는 token을 모으는 단계다. 그냥 token 떼어오면 되는건데 왜 굳이 모으는 방식이 ignore, add, proj 3가지나 있냐고 물을 수 있는데 이건 ViT 기본 구조에서 image embedding할 때 readout 이라는 token을 추가해두기 때문이다. 이건 원래 classification할 때 도움되라고 넣은건데 여기서 안 떼어내서 그렇다. 그래서 readout token을 1) 버릴 것인지 2) 각각에 더해줄 것인지 3) Mlp로 같이 처리해줄 것인지 차이다. 다 떠나서 read는 token 꺼내오기다. 이론적 의미는 없음 |
  |
꺼내면 token들을 다시 H x W 형태로 concat하고 사이즈를 원하는 해상도로 맞추어 쓰면 된다. ViT token은 입력 크기에서 변화가 없기 때문에 어느 레벨에서 꺼내도 항상 입력 크기와 같다. 근데 뒤 CNN decoder에 넣을 때 low to high resolution으로 넣어주기 위해서 사이즈를 줄이거나 늘려주는 것이다. resample은 interpolation 아니고 그냥 stride convolution으로 뽑아오는 방식이다. downsample, upsample 둘다 가능 (왜 굳이 해상도를 낮추는진 모르겠음... 그냥 모든 레벨에서 원본해상도 쓰면 안되나. downsample이 안좋다고 했으면서) CNN decoder에서 사용하는 fusion module들은 refinenet에서 사용했다. 그림 가장 오른쪽을 보면 됨. fusion module 내부에 residual convolution unit은 다음과 같이 생겼음  |
 |
inference할 때 이야기 같은데 inference할 때 이미지 사이즈가 224x224가 아닐 경우, 문제가 생길 수 있는데 이 경우 16으로 나눠지기만 하면 타일링을 하던 뭐를 하던 연산은 가능하다. 이 때 positional embedding 값은 interpolation으로 맞춰서 사용하면 된다고 한다. |
  |
| monodepth task의 backbone 구조로 썼을 때 효과가 좋았고 |
 |
|
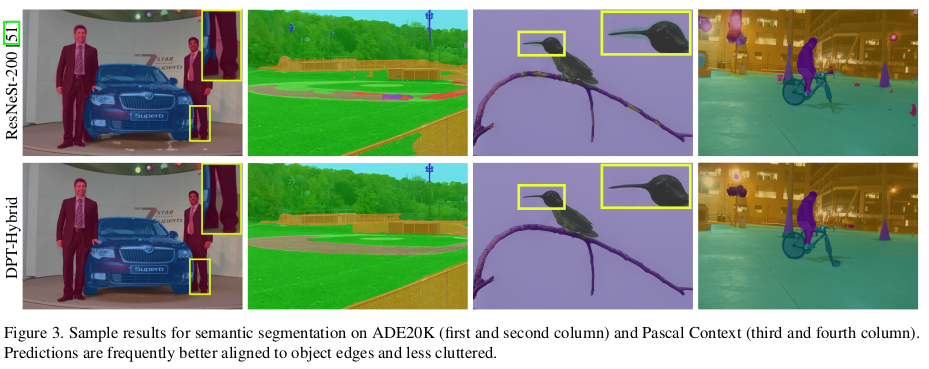
| semantic segmentation에서도 효과가 좋았다고 한다. 다른 테이블 수치들은 크게 볼 필요 없을 듯. 구조의 제안이니까. |
반응형