반응형
내 맘대로 Introduction

이 논문은 pretrained ViT backbone을 학습시켜두는 방법론을 설명하는 논문이다. Masked image modeling(MIM) 기법으로 사전 학습시킨 ViT backbone이 다른 vision task에 사용되었을 때 성능 향상에 기여했다는 논문들이 다수 등장함에 따라 그 확장 판 논문이다.
핵심 아이디어는 하나의 이미지로만 학습시키던 MIM 기법을 두 개의 이미지로 학습시키는 파이프라인으로 만들고, 그 두 개의 이미지를 같은 공간 view point만 다른 이미지로 제한하여 공간 정보를 더 잘배우도록 유도하는 것이다. 공간 정보를 더 잘 배우니 3D vision task의 backbone으로써 더 적합하다는 주장도 펼친다.
메모하며 읽기
  |
| MIM이라는 것이 이미지의 특정 token을 masking하고 encoder-decoder를 거쳐 masked region을 복원해내도록 학습시켜 네트워크가 이미지 정보를 self-supervised로 배우길 유도하는 방법론이다. Croco는 이걸 같은 공간에서 view point만 다른 2개의 이미지를 이용하여 변형한 것이다. 그림과 같이 첫번째 이미지에는 masking, 두번째 이미지는 원본 그대로 같은 encoder로 encoding한 뒤 decoder로 첫번째 이미지의 masked region을 복원하는 방식이다. 이러면 유도되길, 첫번째 이미지의 masked region에 대한 정보를 두번째 이미지에서 cross attention으로 가져와서 복원하게 되므로 네트워크가 어디가 어디와 같은 영역이고 다른 영역인지 분간할 수 있게 된다는 것이다. 즉, correspondence를 찾는데 특화되는데 3D geometric task에서는 correspondence가 그 시발점에 있기 때문에 이러한 학습 기법이 효과적이라고 주장한다. |
  |
| encoder는 그냥 ViT encoder를 쓴다. 224x224에 patch 사이즈 16 쓰는 것도 똑같으며 positional embedding도 sinusoidal 로 쓴다. |
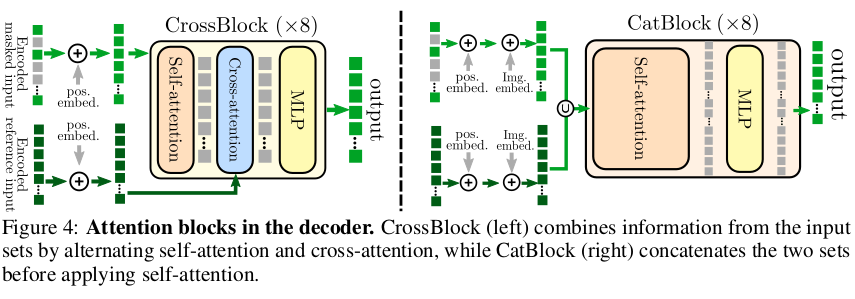  |
| Decoder도 ViT 기반이긴 한데 두 이미지에서 온 token을 섞어야 하기 때문에 구조적 변형이 조금 있다. 여러 선택지가 있지만 대표적으로 2개를 제안하고 있다. 첫번째는 첫번째 이미지 token을 메인으로 가져가되 중간에 cross attention layer를 넣어서 두번째 이미지 token 정보를 섞어주는 디자인이다. 두번째는 첫번째 이미지 token과 두번째 이미지 token을 concat해서 처음부터 합치는 방식으로 self-attention layer로만 조합되어있다. 그냥 concat하면 이미지 구분이 안되기 때문에 learnable image embedding를 더해주는 스텝이 사소하게 추가되어 있다. Crossblock을 쓰면 메모리를 더 먹지만 연산량이 낮고, Catblock을 쓰면 메모리는 덜 먹지만 연산량이 많아 선택적으로 써야한다고 한다. 여기선 Cross block을 선호한다. |
  |
| 학습 loss는 rgb reconstruction 결과와 l2 loss를 먹이는게 끝이고 그 비중만 masking region 영역에 비례하도록 조정된다. 이렇게 학습이 완료되면 encoder만 떼어내서 다른 vision task의 backbone으로 쓰면 된다. 특별히 binocular 즉, 이미지가 2장 입력되는 task에 적용하긴 더 편한데 학습 시 구조와 동일하게 유지하면서 decoder까지 같이 쓰면 된다고 한다. |
 |
 학습 시 사용되는 이미지 조합은 위와 같고, masking ratio는 0.9가 제일 좋았다고 한다. |
 |
| Cross block과 Cat block 차이는 크지 않고 task 별로 미미한 차이여서 골라서 쓰면 된다고 한다. default는 cross block. |
 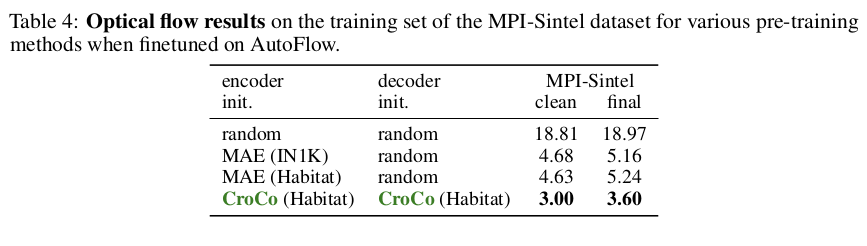 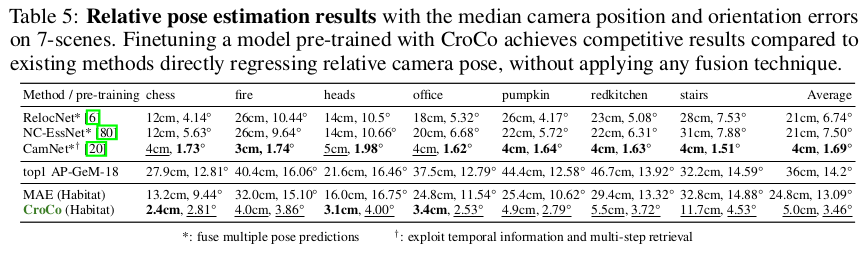 |
| 그냥 MIM보다 성능이 뛰어나며 다른 pretrained backbone 대비 성능도 뛰어난 편. |
반응형