반응형
내 맘대로 Introduction

TSDF fusion + neural rendering을 섞은 논문이다. depth 센싱이 가능한 상태에서 3D reconstruction을 하는 방법이 대표적으로 TSDF인데 pcd registration + depth averaging 방식이다 보니 되게 smoothing되는 단점이 있는데 이 문제를 neural rendering으로 풀고자 했다. 따라서 TSDF 컨셉을 따라가는 local level과 neural rendering을 따라가는 global level로 나누어 네트워크를 설계했다.
메모하며 읽기
 |
|
  |
전체는 depth feature를 TSDF 하듯이 시점 별로 fusion하는 local level fusion, neural rendering 컨셉으로 한 번더 보정하는 global level fusion이다. local level fusion에서 feature를 모아 만든 neural volume은 decoder를 통해 SDF volume으로 변환되고, global level fusion은 이 SDF volume으로부터 시작한다. feature to SDF decoder는 voxel 하나하나마다 적용되는데, 둘러싸고 있는 8개의 neighbor를 trilinear interpolation해서 continuous하게 계산한다. (8개면 모든 방향이 아닌데...어떻게 했다는건지 아마 대각선 8방향 말하는 것 같다.) 특이점은 8개의 neight를 사용할 때 중심 voxel 대비 상대 좌표값을 사용했다는 것이다. 어차피 SDF는 가장 가까운 surface까지의 거리이므로 국소적으로 봐도 충분하다는 가정인 것 같다. |
  |
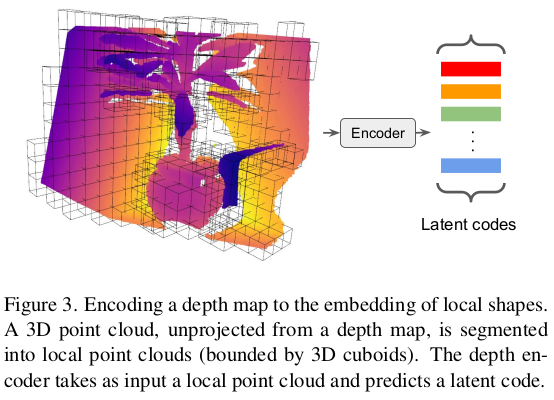 제일 시작점인 depth feature는 어떻게 뽑냐. depth 이미지를 back projection한 뒤, global 좌표계로 바꾸어 3D point를 만든다. 그리고 PointNet 수정 버전을 통과시켜 feature로 만든다. PointNet은 ShapeNet 데이터를 이용해 학습해둔 상태이고 사용한 loss를 수식(2)와 같이 GT SDF supervision이다. 간단. |
  |
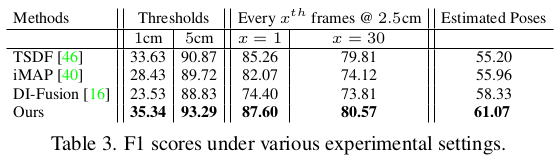
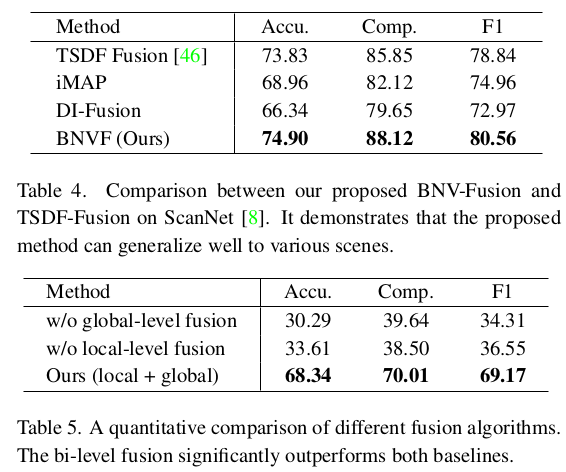
feature를 뽑았고 feature + depth로 neural volume 만드는게 그 다음 단계인데 TSDF랑 동일하다. depth로 어떤 한 위치의 voxel에 feature를 누적해서 채워주는 식으로 진행되는데 voxel이 겹칠 경우, weighted sum을 해준다. TSDF에서는 그냥 1:1로 해도 큰 영향없어서 1:1로 했다는게 기억난다. 그 다음 단계는 neural volume을 SDF volume으로 decoder를 통해 바꾸고 ray 마다 predicted depth from SDFs vs input depth supervision을 통해서 재튜닝해주는 단계다. depth sensor 정확도를 신뢰할 수 있다는 것이 전제 조건인 듯하다. 정말 간단한 아이디어인 듯. 딱 TSDF를 조금만 보완하자는 목적이 뚜렷하게 보인다. |
 |
 |
  |
 |
 |
반응형