반응형
내 맘대로 Introduction

NeRF 류 알고리즘의 핵심이 multiview의 힘을 쓴다는 것인데 당연하게도 multiview constraints가 강할수록 학습이 잘 될 것이다. 두 가지 방법으로 multiview constraint를 알고리즘에게 강화해줄 수 있을텐데 첫번째는 카메라 포즈를 더 정확히 주는 것 두번째는 학습할 때 multiview 관련 support를 제공해주는 것이다. 이 논문은 후자를 시도해보았다.
개인적으로 틀린 말 하나없고 성능도 좋았다고 하니 다 납득했는데 그저 그랬다. 특별할 것까진 없어서 contribution이 무엇인지 뚜렷하게 보이지 않고 학습 시간 측면에서 trade-off가 있을 것 같아서 전체 이득인지는 모르겠다.
메모하며 읽기
  |
|
 |
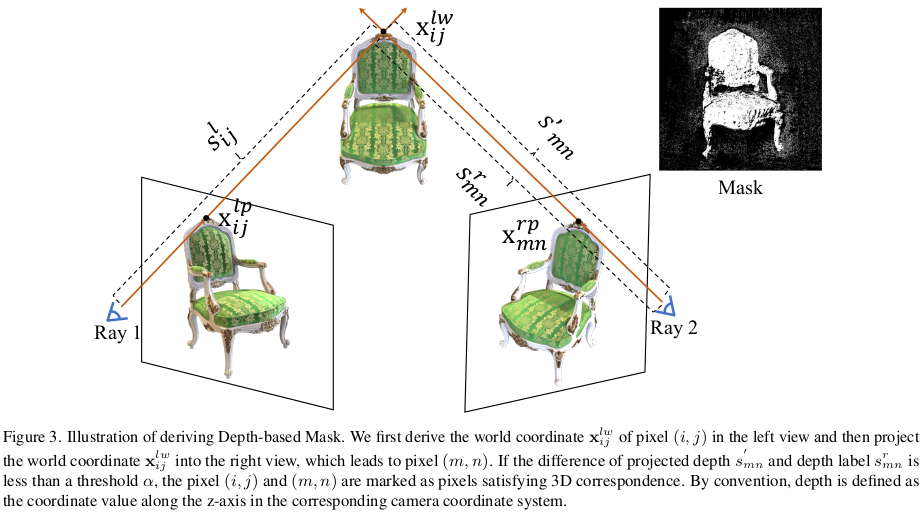
(Sec 3.1 background는 NeRF 설명하는 부분이라 패스) Multiview consistency도 사실 그냥 알고 있는 내용이라 패스할까 하다가 notation 때문에 짚고 넘어간다. 시점 A의 (i,j)가 시점 B의 (m,n) 과 카메라 포즈+depth를 이용해 warping했을 때 color가 맞아 떨어져야 한단 소리다. |
   |
복잡하게 쓰여있지만 결국 left image to right image warping에 관한 수식이다. intrinsic, extrinsic 곱한다는 이야기를 이렇게 길게 써놨다. warping할 때 depth가 필요한데 ray 별 depth를 계산하는 것은 NeRF에서 sum 한 번이면 계산할 수 있으니 사실 상 주어진 값이다. 그렇게 warp(i,j) - (m.n) 차이를 계산하고 일정 threshold 미만인 곳만 mask를 생성해서 loss 가중치를 높게 적용해주고 이상일 경우 가중치를 낮춰주는 식으로 multiview constraint를 네트워크에게 강화했다. (진짜 간단....) |
 |
warp(i,j) - warp(m,n)으로 loss를 구성하면 둘 다 0으로 가버릴 수도 있으니 GT 랑 supervision을 매겼다는 소리같다. 당연한 소리; |
  |
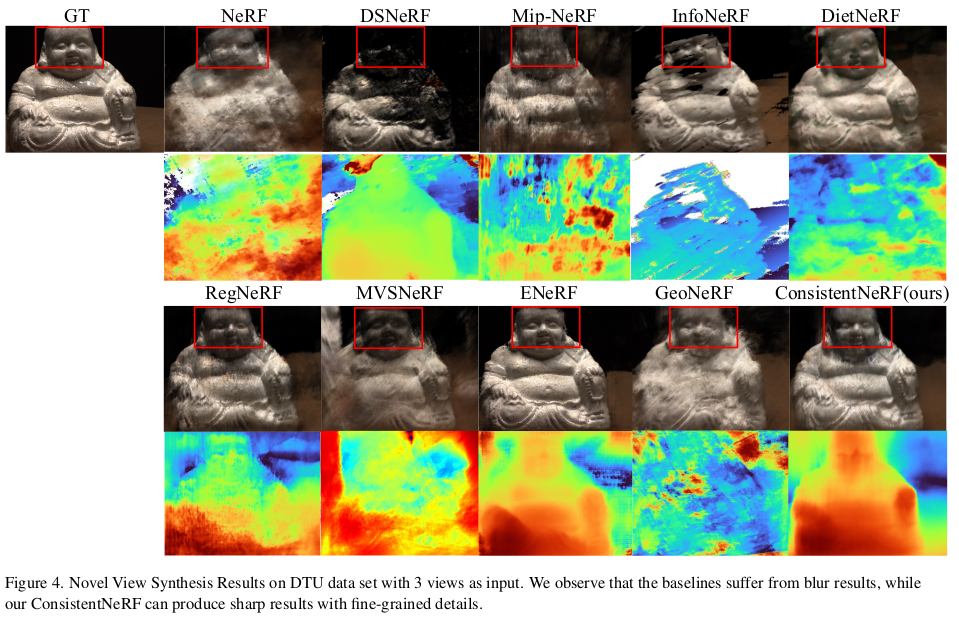
(여기서 조금 멀리 갔다 싶었는데...) MiDAS라는 monodepth 알고리즘에서 나온 scale invariant depth를 supervision으로 추가해준다. scale이 없는 GT이기 때문에 predicted depth에서 scale을 제거해준 뒤 supervision을 걸었다. 전제 조건이 MiDAS가 scale은 없지만 그래도 형상의 relative depth는 정확하게 표현한다는 것이다. |
 |
 |
 |
 |
반응형