반응형
내 맘대로 Introduction

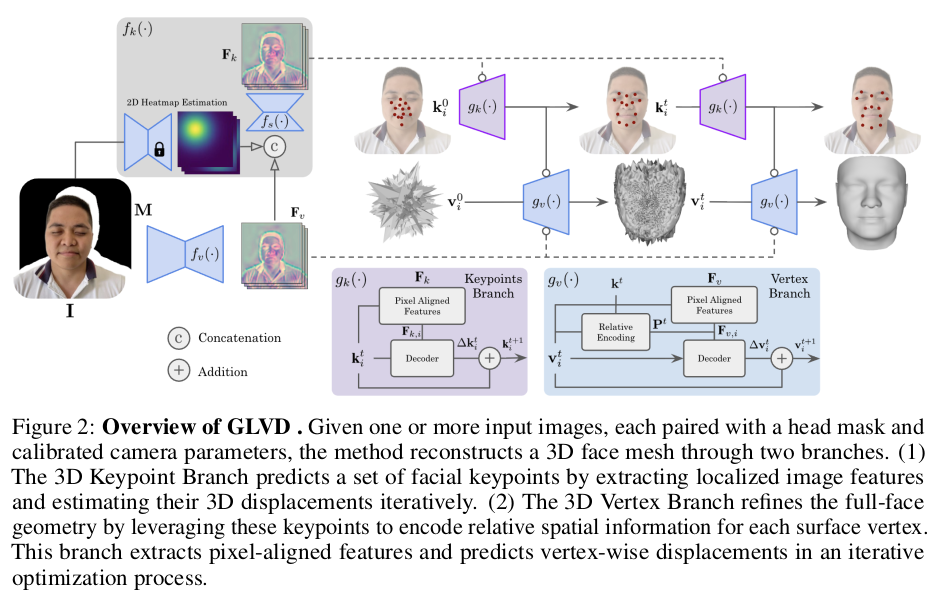
그림만 보고 mesh diffusion 같은 컨셉인 줄 알았는데 알고보니 LVD의 얼굴 버전이더라. 단순히 말하면 LVD랑 똑같이 projected vertex 위치에서 이미지 feature를 뽑아가면서 vertex 위치의 보정량을 예측하는 네트워크를 학습하는 건데, 얼굴이라는 도메인을 살려서 keypoint 에 대해서 relative postiion encoding을 취하면서 진행하면 성능이 좋다는 얘기.
사실 크게 와닿는 내용은 아닌 것 같다. 단순 메모용.
메모
 |
|
 |
LVD를 얼굴에 대해서만 학습할 건데 keypoint 추정하는 모듈을 같이 학습해서 keypoint가 나머지를 guide한다는 의미. |
  |
2D keypoint dectector에서 얻은 heatmap을 이용해 image feature에 attention을 걸어주고, keypoint displacement를 예측하는 모듈을 추가했다. 쉽게 말하면 vertex LVD + keypoint LVD를 서로 연결했고 keypoint relative positional encoding을 추가한 것. |
 |
이부분은 LVD랑 완전 똑같아서 별 특이점이 없다. SDF 학습으로 encoder를 사전학습해두면 성능이 좀 더 좋다는 코멘트 정도인데 핵심은 아닌듯. 내용 없음. |
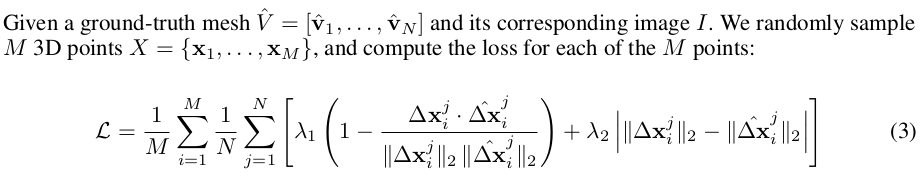 |
l2 loss 말고 normal loss 형식으로 vertex의 방향이 잘 맞도록 해줬다. 이 역시 특별해보이진 않는다. 이거 accept 안될 것 같은데... |
  |
  성능 수치로 도전하는 논문인 듯. |
반응형
'Paper > Human' 카테고리의 다른 글
| Generative Human Geometry Distribution (0) | 2025.10.27 |
|---|---|
| Topologically Consistent Multi-View Face Inference Using Volumetric Sampling (0) | 2025.10.16 |
| Learned Vertex Descent : A New Direction for 3D Human Model Fitting (0) | 2025.10.16 |
| 3DGH: 3D Head Generation with Composable Hair and Face (0) | 2025.08.06 |
| GSGAN: Adversarial Learning for Hierarchical Generation of 3D Gaussian Splats (0) | 2025.08.04 |