반응형
내 맘대로 Introduction

CGS-GAN 코드를 보니 뭔가 안쓰이는 코드도 구현되어 있고, dummy 값으로 채워넣는 부분도 있어서 뭐지 싶었는데, GSGAN 코드를 그대로 복붙하고 수정해서 쓴거더라. 사실 이 논문의 코드를 분석하고 개선한 뒤, 데이터셋까지 큐레이션한게 CSG-GAN이었다. 이 논문이 시간적으로 앞섰을 뿐 아니라 그냥 기반이 된 논문. 읽어보니 디테일한 노하우들은 다 GSGAN에서 나왔다.
개인적으로 저자의 이력을 보니, 몇 년 전부터 GAN을 다루시는 분인 것 같은데 그 경험 덕인지 이미지 대비 난이도가 높은 3D GAN 프레임워크를 잘 디자인하신 것 같다. 단독 저자인 것도 인상적. 한국 분이시기도 해서 얘기 나눌 기회가 있었음 좋겠다.
논문 핵심은 generator 자체의 구조를 제안한 것 + 안정적 수렴을 위해서 gaussian primitive들을 coarse to fine으로 풀길 제안한 것 + 그걸 끄끝내 수렴시켰다는 것이다. 난 GAN을 다뤄본게 styleGAN2 재구현해서 학습시켜본 것이 끝인데 그 때 왜 안되지의 늪에서 못 벗어난 기억이 난다. 결국 제안된 arcitecture를 써야만 수렴됐었는데 그만큼 구조, 하이퍼 파라미터, 데이터 등 조금만 맘에 안 들어도 발산해버리는 GAN을 수렴시켰다는 것이 작아보이지만 더 대단하다.
메모
 |
|
 |
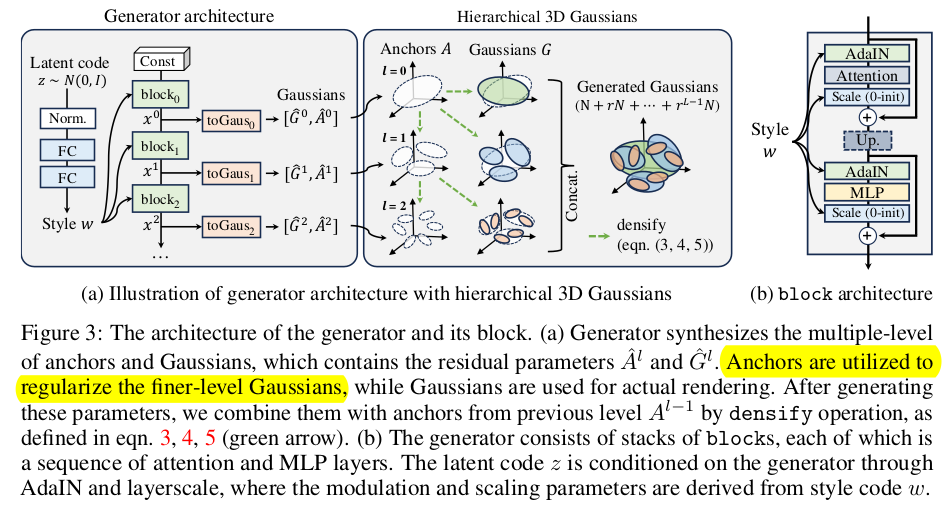
random latent z에서 realistic image를 렌더링할 수 있는 3DGS를 "생성"해내는 것이기 때문에 자유도가 미친듯이 높다. 그냥 3DGS도 SfM에 의존한 초기화가 없으면 쓰레기처럼 수렴하는 문제가 있는데 GAN은 오죽했을까. 그래서 핵심은 3DGS primitive들을 regularization하는 것. 1) 첫 레벨에서 coarse 예측을 한 뒤, 2) 그 이후 레벨에서는 이전 레벨 예측 값에 더해질 residual 형태로 구한다. 위치가 제일 중요한데, 현 레벨의 위치는 이전 레벨 위치 + 이전 레벨의 회전/스케일을 반영하는 residual로 구한다. 이렇게 하면 이전 레벨에 biased된 예측을 할 수 밖에 없다. |
  |
스케일이나 다른 opacity, rotation/color 같은 것들도 다 residual 형태로 구현했고, scale은 특별히 하나 "더 이전 레벨보다 스케일이 작을 것." 조건을 추가했다. coarse to fine 컨셉이므로 fine level에서는 좀 더 디테일을 표현하는 3DGS가 생성되길 기대한다. 따라서 scale이 더 클순 없다. residual scale도 음수가 되길 유도하고, constant scale 값을 하나 음수로 지정하고 무조건 빼줘서 무조건 작아진다는 것을 보장함. scale이 작아진다는 것은 position을 구하는 것에도 영향을 준다. 왜냐면 수식(3)을 보면 앞에 scale이 곱해지기 때문. |
 |
|
  |
구조도 인상적. latent code가 style처럼 들어가도록 했고 learnable point cloud에서 시작함. transformer block은 point feature를 뽑아내는 역할만 하고 각 레벨에서 to gaussian MLP가 따로 붙어서 decoding하는 구조 densify는 3DGS densification 의미하는 것이 아니라 각 레벨에서 gaussian 예측을 lambda 배 씩 많이 하게 디자인했는데 그 결과를 반영해서 최종 3DGS만들어내는 과정일 뿐. 단순 작업이다. --------- CGS-GAN에서는 toGauss 들어가기 전 point feature를 upsample하는 layer를 추가한 것이 차이. 이렇게 보니까 정말 GSGAN 분석하고 튜닝개선한 느낌이 강하다. |
 |
이상적으로는 이전 레벨 Gaussian이 다음 레벨 Gaussian의 최고 초기값이 되면 좋지만 실제로는 그렇지 않았나보다. 렌더링을 고품질로 하기 위한 3DGS 값들과 다음 레벨을 위한 기준으로써 3DGS 값들 간의 차이가 조금 있었나 봄. 그래서 toGauss 모듈은 아쉽지만 렌더링을 위한 이 둘을 나눠 2번 예측하도록 했다. |
 |
Generator 디자인할 때도 모듈을 교체했다. transformer based GAN 디자인할 때 많이 쓰이는 AdaIN을 이식했고 positional encoding을 제외했다. coarse에서는 self attention을 fine에서는 local attention을 사용하도록 교체했음. 그리고 layerscale 추가 이건 attention의 출력을 조절하는 파라미터를 하나 더 둬서 학습 안정성을 높이기 위한 목적. |
  |
GAN loss가 주축이지만, 안정적인 학습을 위해서 discriminator의 gradient를 억제하는 reguliarzation 추가. f(t)로 감싸주는 것 추가. ------ 보조적으로 이미지와 카메라 pose 간의 binding을 강화하기 위해서 constrastive learning을 추가했다. 이미지에서 뽑은 pose embedding과 카메라에서 뽑은 pose embedding이 유사하도록 당기는 것. pose embedding은 discriminator의 입력이 되기에 학습 안정성에 도움이 됨. ------ 3DGS의 위치는 평균이 0이 되도록, 억제 (머리통이라서 가능한 것) 그리고 끼리끼리 가깝도록 억제했다고 함. |
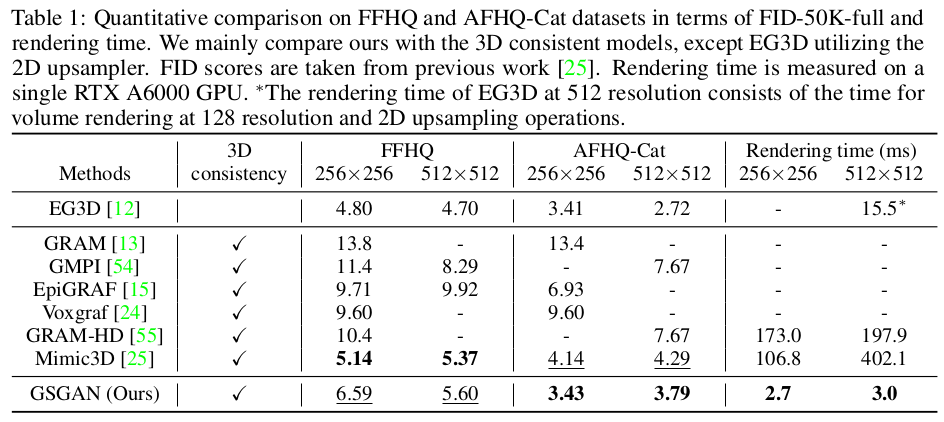 |
수치적으로 FID 앞섬. |
 |
|
 |
 |
그냥 냅다 학습하면 발산해버리고, scale을 clipping하는 정도로만 해서는 발산을 막을 뿐 수렴은 안된다. 제안한 방식으로 했을 때 수렴이 가능했다. |
 |
regularization이 빠질 때마다 3DSG들이 얼굴 제위치에 없는 것을 볼 수 있음. |
반응형
'Paper > Human' 카테고리의 다른 글
| Learned Vertex Descent : A New Direction for 3D Human Model Fitting (0) | 2025.10.16 |
|---|---|
| 3DGH: 3D Head Generation with Composable Hair and Face (0) | 2025.08.06 |
| CGS-GAN: 3D Consistent Gaussian Splatting GANsfor High Resolution Human Head Synthesis (0) | 2025.07.30 |
| Neural Facial Deformation Transfer (0) | 2025.06.10 |
| Human Hair Reconstruction with Strand-Aligned 3D Gaussians (0) | 2025.05.23 |