반응형
내 맘대로 Introduction

VGGT가 best paper 받은지 얼마나 됐다고 바로 개선 작업에 착수해서 VGGT를 이겨먹은 모델이 나왔다. VGGT를 잘 뜯어보고 단점을 떼어내고 데이터를 더 먹여서 성능이 높인 것 같다. 들어간 전기와 데이터에 경의를 표한다.
메모
 |
가장 먼저 VGGT의 단점으로 꼽은 것은 reference view의 필요성이다. DUST3R도 그렇고 기준 시점을 제외하면 나머지 시점의 output들은 모두 자기 coordinate가 아닌 기준 시점 coordinate로 뱉어야 한다. 따라서 기준 시점과 멀찍이 있을 수록 어렵기 때문에 성능이 기준 시점 선정에 따라 불안정하다는 것을 꼬집는다. 그래서 하고자 하는 것은 VGGT에서 기준 시점이라는 개념을 삭제해버리는 것. |
 |
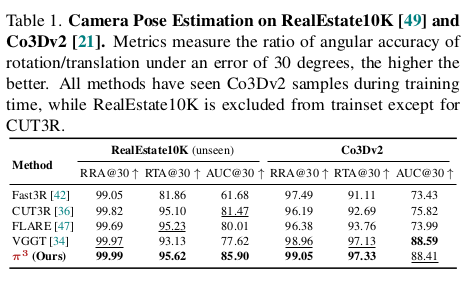
결론을 먼저 말하면 1) 시점 순서 상관없음 2) scale 상관없음 3) transform 상관없음 총 permutation invariant한 특징 3가지를 넣어서 학습했다. 그래서 "p" ermutation "i"nvariant "3" 다. 그 결과 수렴 속도가 더 빨라졌고, 모델 크기를 키웠을 때 성능이 증가하는 폭도 커졌다고 한다. |
 |
|
  |
먼저 가장 중요한 입력 이미지의 순서와 전혀 상관없이 성능이 나오게 하기 위해서 기준 시점이라는 개념 자체를 없앤다. VGGT에서 reference 시점을 구분하는데 일조했던 camera token을 삭제해버림. --------- 구조는 DINOv2를 사용했고 view-wise, global self attention layers를 썼고 이렇게 설명했는데 자세히 뒤에 읽어보면 pretrained VGGT 가져다 썼다. |
   |
그 다음은 scale을 다뤘다. DUST3R도 그렇고 scale ambiguity를 풀기 위해서 결국 normalization이 껴있었고, 모두 기준 시점의 scale에 맞췄다. 하지만 기준 시점이 사라진 pi3에서는 scale ambiguity를 풀면서 모든 시점에서 공유할 scale 하나를 지정해야 하는 문제가 생김. 그래서 중간에 최적화를 하나 꼈다. 모든 시점에서 global coordinate로 pointmap을 내뱉도록 하고, 이 모든 것을 쌓아서 GT와 Least squre를 풀어서 scale을 뽑는다. 이후 이 scale이 GT처럼 사용되어 scale loss에도, 뒤에 trasnformation invariant loss를 구현할 때도 쓰인다. --------- 다시 말하면 scale ambiguity는 특별히 푼게 아니라 늘 풀 듯 normalization으로 그냥했고 기준 시점 대신 global scale 하나를 최적화로 풀어내도록 했다. 마이너하게 pointmap 성능을 높이기 위해서 normal loss도 같이 추가했다고 한다. |
  |
마지막으로 global transform에 대해서 invariant하게 만들었다. 정확히는 유도했다. 카메라 포즈와 loss를 계산할 때 absolute form으로 GT camera pose와 비교하지 않고 relative form으로만 비교를 했다. 다른 말로 GT의 카메라 상대 구조만 강조하면서 loss를 걸었다. T_i 같은 absolute pose는 사실 point map loss를 통해서 업데이트되는 영향이 주로 있고 나머지는 relative camera pose loss로 밀고 당기면서 조정 학습되는 모양인 것 같다. ---- 하나 relative pose로 loss 계산할 때 문제가 scale이다 역시. rotation은 scale과 애초에 무관하지만 translation은 아니다 scale이 끼면 다르다. 따라서 앞서 구한 scale을 여기서도 쓴다.  결과적으로 더 정확해진다는 것인데 분석이 위와 같이 pose PCA의 eigenvalue로 비교해준다. 이게 맨처음엔 이해가 안됐었는데 내가 이해한 바는 다음과 같다. 카메라 포즈는 6DOF라서 사실상 무한의 가능성을 갖고 있는데 우리가 촬영할 때 등장하는 카메라 포즈는 그 중 극히 일부다. 이 말을 반대로 하면 무한한 카메라 포즈 중에 현실 촬영에 사용되는 카메라 포즈들은 그리 많지 않아 굉장히 저차원일 것이라는 말. PCA를 돌려보았을 때 저차원으로 표현이 가능한 결과가 나오면 나올 수록 현실 촬영에 있을 법한 카메라 포즈가 추정된다는 말이다. 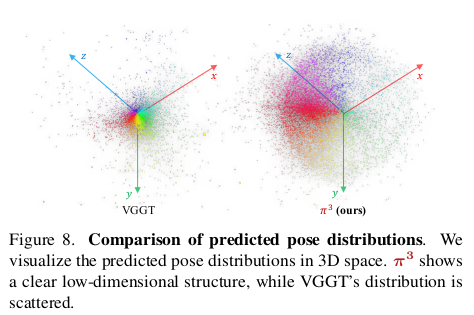 |
 |
 |
 |
 |
 |
 |
 |
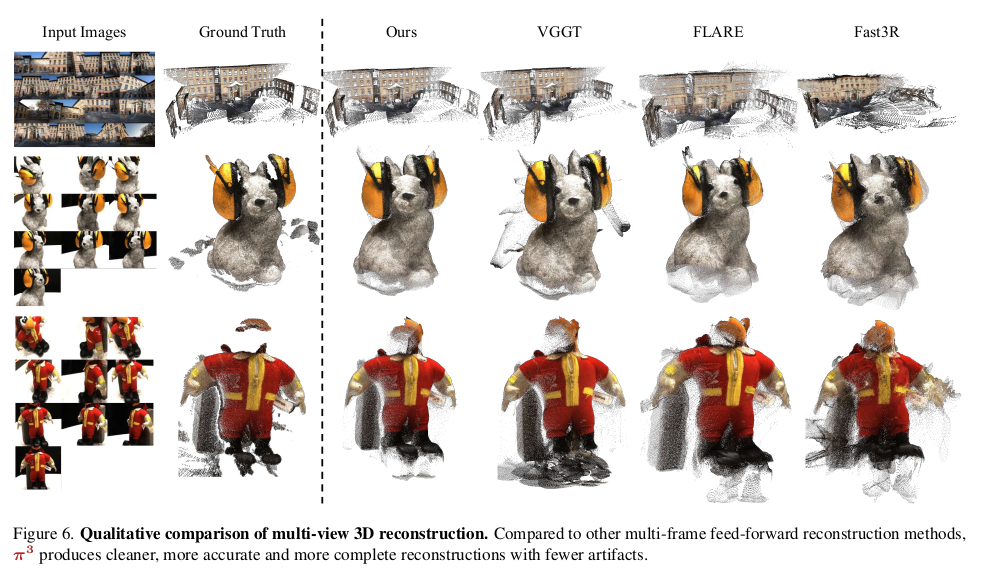
성능이 크게 오른다는 걸 수렴 속도 측면에서나 scalability 측면에서도 보여주는게 참 대단. 규모의 논문이다. |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| Gaussian Opacity Fields: Efficient Adaptive Surface Reconstruction in Unbounded Scenes (0) | 2026.01.20 |
|---|---|
| Deformable Beta Splatting (0) | 2025.06.09 |
| Large Steps in Inverse Rendering of Geometry (0) | 2025.04.29 |
| Towards Realistic Example-based Modeling via 3D Gaussian Stitching (0) | 2025.04.18 |
| SeamlessNeRF: Stitching Part NeRFs with Gradient Propagation (1) | 2025.04.16 |