반응형
내 맘대로 Introduction

요즘 3DGS을 seamless integration하는 방법을 좀 알아보고 있는데, 2023년 NeRF에서 구현한 논문이 있길래 참고 삼아 읽었다. 각기 다른 대상을 담은 NeRF MLP (정확히는 TesorRF Vector-matrix)가 주어졌을 때, 이를 두 개를 합쳐 마치 하나였던 것처럼 렌더링하는 방법론이다. 핵심은 color tone을 업데이트해서 자연스럽게 이어붙이는 과정.
단순히 color tone만 업데이트하면 잘 안될 것 같은데, gradient를 이용한 loss로 보강한 것이 핵심
메모
 |
|
  |
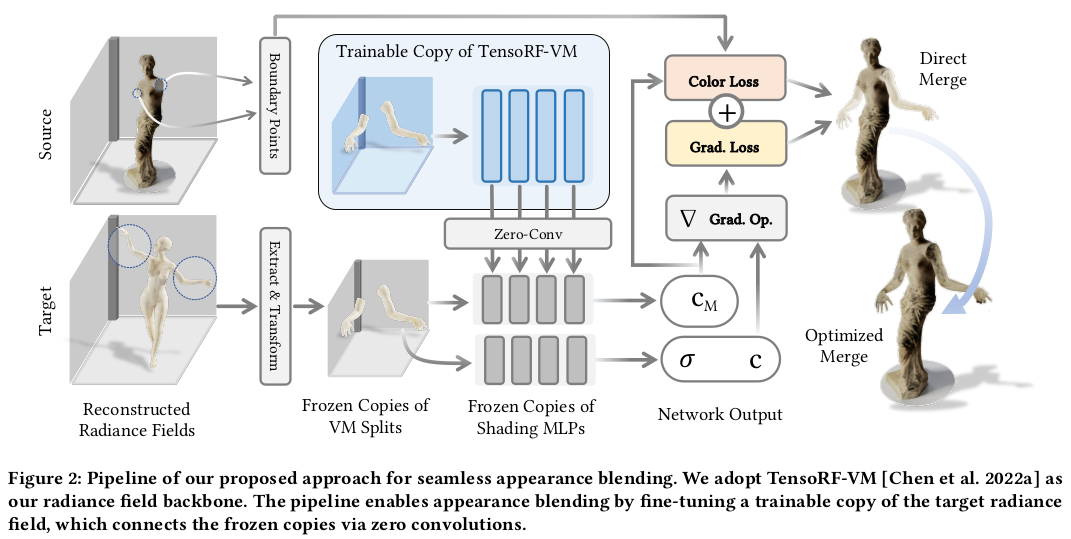
1) 기본적으로 TensorRF를 backbone으로 쓴다. TensorRF는 vector와 matrix로 공간을 표현하는 representation을 쓰기 때문에 유리한 점이 많다. 타겟 볼륨을 정하면, 해당 볼륨에 대응되는 vector, matrix만 잘라서 쓰면 되기 때문에 직관적. 연산 속도를 낮추는데도 많이 도움이 되었을 것 2) target을 source로 가져와서 붙이는데 (이름이 거꾸로지 않나?) 일단 두 대상 TensoRF를 고정한다. color를 빼고 그리고 zero convolution만 추가한 뒤, color는 추후 tone을 보고 보정될 수 있도록 learnable로 열어두는 것. controlnet처럼 사용된다. 3) target -> source 어느 위치에 붙일 것인지느 손으로 계산해둬야 한다. M 을 직접 찾아두는 것. ------------------- 학습할 때는 3D 위치 x 당 어느 TensorRF가 지배적인지 찾아둔다. 기본적으로 opacity가 해당 위치에서 가장 높은 모델을 고른다. 이 때 모델마다. 학습시 opacity scale이 다를 수 있으므로 이것을 다루기 위해 beta를 추가한게 트릭. 결국 접합 부위에서 가장 불투명한 모델 값을 따라가겠다는 직관적 선택. |
 |
접합 부위에 어떤 모델을 쓸 건지 정해졌다면 그대로 렌더링해서 color와 probability 같은 것을 렌더링 하면 학습 준비 끝. |
  |
접합 부위 근처에서 이제 렌더링을 반복하면서 loss로 업데이트하는 식으로 접합 부위의 seam을 없앨 것인데 렌더링할 각도를 정하는 것도 중요하다. 임의로 랜덤 view point를 사용할 경우에는 각 tensorRF가 학습될 때 사용됐던 view point랑 너무 다를 여지가 있어서 그리 좋은 렌더링 퀄리티가 안나올 것이다. 따라서 접합 부위에 지배적인 모델이 선정되면, 해당 모델을 학습할 때 썼던 카메라 view를 가져와서 view direction을 생성했다고 함.  확실히 봤던 view direction에서 렌더링 퀄이 좋기 때문에 이 direction들을 갖고 tuning까지 해야 잘된다는 결과. |
   |
이제 슬슬 color tone을 어떻게 업데이트하는지 설명한다. 기존 source에 새로운 target을 접합하는 방식인 만큼, 일단 기준 점을 맞닿는 딱 경계면일 것이다. 위 마네킹으로 보면 팔뚝이 붙여지는 부위. 이부분의 위치를 손으로 찾을 수도 있겠지만 복잡하므로, 일단 rule을 세우길. 지배적인 모델이 원래 source인 부분을 경계로 정의했다. 물론 나머지 파트들도 따라올테지만, target model을 볼륨에서 벗어났다면 계산 안하면 된다. ----- source가 지배적인 위치에 대해서, target model이 만약 색상을 만들어낸다면 (접합 범위 안이라면) target model이 만들어내는 색상과 source가 만들어내는 색상이 가깝도록 최적화 한다. 이러면 딱 맞닿는 경계부터 색상 톤이 맞아들어가기 시작함. |
 |
  (notation이 참 맘에 안든다. 이해하기 어렵게 되어있음) 추가적으로, 각 위치 별로 지금 통합된 모델의 색상 gradient를 계산 한뒤, 해당 위치에 색상을 생성하는 (범위 안에 들어와있는) 다른 모델들의 색상 gradient와 유사하도록 최적화했다. 이게 무슨 말이냐면. 어느 한 점의 색상을 모델 A, B, C ... 등 제각각으로 만들어내고 있을텐데 이 색상 변화 폭이 전부 비슷하도록 만드는 것. --------- 그러면 앞선 loss가 맞닿는 부분의 색상을 업데이트함과 동시에 gradient를 타고 나머지 부분에도 색상이 전파되는 모양. |
 |
학습은 처음부터 TensoRF를 다시하면 당연히 망가지니까 웬만하면 다 freeze 해두고 controlnet처럼 zero convolution +@로 업데이트만 할 수 있도록 adapater를 붙이는 식으로 구현했다. |
 |
|
 탑 안에 개구리를 넣은 것이기 때문에 맞닿는 면적 많아서 개구리 전체가 갈색으로 변한 것처럼 보임. |
 |
 |
|
 |
 |
 gradient propagation이 되게 좋은 컨셉인 듯. |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| Large Steps in Inverse Rendering of Geometry (0) | 2025.04.29 |
|---|---|
| Towards Realistic Example-based Modeling via 3D Gaussian Stitching (0) | 2025.04.18 |
| Equivariant Point Network for 3D Point Cloud Analysis (0) | 2025.03.21 |
| VGGT: Visual Geometry Grounded Transformer (1) | 2025.03.19 |
| GSTAR: Gaussian Surface Tracking and Reconstruction (0) | 2025.01.22 |