반응형
내 맘대로 Introduction

GGHead도 대단하다고 생각했는데 이에 뒤이어 곧바로 GSGAN이랑 이 논문이 나왔다. 3D GS GAN을 만든 것인데 이전보다 pose variation에 강건하고 3d consistency가 더 확보된다는 점이 차이다. 학습 데이터는 동일하나 섬세한 gradient handling과 네트워크 구조 변화로 성능 점프를 이뤘다는게 멋지다.
핵심은 렌더링을 multiview로 해서 loss를 계산하되, averaged gradient로 업데이트해서 안정성을 높이고 기존 카메라 정보를 넣어주던 부분을 과감히 빼버린 것이다. camera-biased generation에서 완전 3D aware generation으로 넘어가게 한 느낌. 이런 사소한 차이를 관찰을 통해 알아낸 것이 대단하다.
메모
 |
|
  |
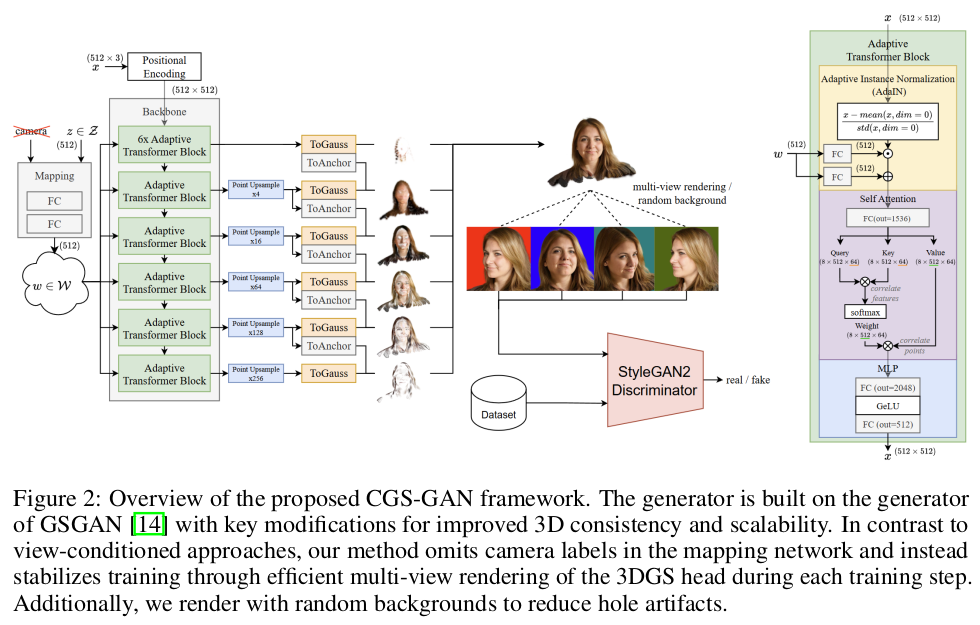
구조 설명이 긴데 생각보단 간단하다. 이걸 수렴시킨 노하우가 더 대단한거지. 1) 512x3의 learnable point cloud 생성 후 positional encoding -> 입력 초기값 같은 느낌 2) latent z를 style vector로 입력 받는 듯한 adaptive transformer block 통과 3) block에서 나오는 512x512 token은 MLP를 통해서 512x gaussian primitives로 변환됨. 4) block은 coarse to fine으로 여러 번 존재하면 각 레벨의 block은 출력이 512x512로 동일함 하지만 뒤에 MLP 통과시키기 직전에 upsample하는 식 -> transformer에서 upsample하지 않기 때문에 메모리 터지지 않음 5) MLP는 Gauss와 anchor를 만드는데 Gauss는 해당 레벨의 렌더링 결과물을 만들어내는 애들이고 anchor는 똑같이 gaussian primitives를 갖고 있지만 다음 레벨 upsampled gaussian들이 왔을 때 더해져서 기준을 잡아주는 역할을 한다. 다른 말로 처음 gauss만 완전 초기값을 스스로 잡고 다음 레벨 gauss부터는 offset을 추정하는 방식. 이전 레벨에서 넘어오는 정보가 있긴 해야 coarse to fine이 되니까. |
  |
multiview를 만드는 것도 어려운데 3D cosistent하게 만드는 과정은 더 어렵다. 특히 GAN처럼 확정적인 입력이 없고 random latent에서 시작하는 경우 더그렇다. 따라서 multiview 를 생성한 결과에서 loss를 먹일 때 gradient를 평균내서 업데이트해서 안정성을 더했다. (loss를 평균내는게 아님.) 각 시점이 3DGS를 업데이트하는 힘을 1/N로 나눠서 담당하도록 한 것. 특정 시점이 너무 과하게 업데이트하면 깨지니까. |
 |
추가적으로 discriminator에 입력을 구성할 때 minibatch-standard-deviation layer를 추가하고 같은 인물의 사진이 2장 이상 들어가지 않도록 했다. 예를 들어, 생성된 multiview 이미지 중 2장 real dataset 에서 2장 이런식으로 구성 하지 않고 생성된 multiview 이미지 를 1+ real datset 에서 3장 이런식으로 atch로 쪼개 구성했다. 이건 discriminator가 더욱 헷갈리게 만들어서 학습을 효과적으로 하기 위함이다. 지금 서로 다른 사람 이미지 N장으로 학습하기 때문에 real data batch에는 항상 다른 사람 이미지가 들어있다. 따라서 mini-batch는 항상 다른 이미지로 가득차있어서 mini-batch std는 항상 클 것. 근데 여기다 생성된 이미지 1장 넣는 것은 여전히 real vs gen으로 std가 크니까 문제가 안되는데 gen이 좀 늘어나면 gen끼리는 std가 작으니까 뭔가 수상한 낌새를 discriminator가 눈치채고 그냥 Fake라고 해버릴 시 학습이 망가지는 것. |
 |
camera view에 대한 정보를 안 넣어주면 3D GAN은 붕괴한다. camera view info를 넣어주는건 불가피 하지만 기존 방식처럼 camera latent를 따로 넣는다거나 이렇게 하지 않고 discriminator 내부에 이미지를 넣을 때 각 이미지 별 feature를 뽑을 텐데 여기다가 camera feature를 더해주는 식으로 섞어주기만 했다. conditional GAN처럼 구성해서 대충 이런 camera feature에서는 이런 이미지가 자연스럽구나 라고 배우게 한 것. |
 |
|
 |
3DGS의 explicitness 때문에 3D consistency는 구조적으로 맞게 되겠지만 그건 이상적일 때 얘기고 아예 수렴이 안될 가능성이 매우 높다. GGHEAD나 GSGAN에서 그래서 입력latent를 넣을 때 camera latent도 같이 넣어줬음 텍스트로든 CLIP으로 든 . 일단 이 저자들도 명확한 방법은 제시하지 못했으나 앞서 언급한 discriminator에 feature level로 넣어주는 것이 도움이 많이 된다고 함. |
 |
|
 |
그냥 흰 배경으로 학습해보니 이상한 artifact가 생김. 그래서 배경 색은 그때 그때 단순색으로 교체해서 썼다고 한다. |
 |
FFHQ에는 손이나 마이크 모자 같은 얼굴 아닌 것들이 많아서 이걸 다 걸러내니 20%인 15000장 정도였다고 함 이걸 다 걸러냈다. |
 |
|
 |
그리고 웃는 사진이 유독 많고 정면이 유독많아서 이런 것도 다 리밸런싱했다고 한다. 손으로 하진 않았고 요즘 잘 나오는 모델을 활용해서 했다고 함. |
 껑충 뛴 성능 |
 |
 |
학습은 H100 4대로 batch 8이었던 거니까 그렇게 가볍진 않다. 3일 걸렸다고 함. |
반응형
'Paper > Human' 카테고리의 다른 글
| 3DGH: 3D Head Generation with Composable Hair and Face (0) | 2025.08.06 |
|---|---|
| GSGAN: Adversarial Learning for Hierarchical Generation of 3D Gaussian Splats (0) | 2025.08.04 |
| Neural Facial Deformation Transfer (0) | 2025.06.10 |
| Human Hair Reconstruction with Strand-Aligned 3D Gaussians (0) | 2025.05.23 |
| DiffLocks: Generating 3D Hair from a Single Image using Diffusion Models (2) | 2025.05.23 |