반응형
내 맘대로 Introduction

ExAvatar와 같은 문제, 다른 접근법. 하지만 mesh는 조금 더 빠르고 mesh 품질이 조금 더 좋은 느낌. rigging은 조금 더 부자연스러운 느낌.
video to animatable 문제를 풀기 위해 SMPL에 3DGS를 할당하고 video sequence를 이용해서 3DGS property를 업데이트하는 방식. 수렴이 되면 3DGS가 그럴듯한 렌더링을, SMPL이 다양한 자세를 제공한다.
이 논문의 전제 조건도 ExAvatar와 같이 SMPLX이 fitting되어있다는 것을 깔고 간다. SMPL face마다 할당된 3DGS가 skinning weight를 갖고 있다는 점이 차이점. skinning weight를 추가로 업데이트하기 때문에 보다 자연스러운 움직임을 할 수 있도록 설계했다. (근데 결과 보면 그냥 SMPL weight 쓰는게 더 자연스러워보이는 것 같기도)
내가 볼 때 이 논문의 핵심은 normal cue를 이용해서 photometric loss만 사용했을 때보다 강하게 3DGS position 업데이트를 했다는 것이다. 3DGS가 surface 형상을 닮을 수 있도록 더 강제해서 mesh가 좋아진 것은 ExAvatar에 비해 두드러지게 눈에 띈다.
구현을 많이 한 것도 아니고 그냥 있는거 활용해서 처리한 것도 간단해서 좋다.

속도를 하나의 관점으로 계속 보여주는 것도 좋았다.
메모
 |
고정된 카메라에서 촬영된 비디오를 가정 매 프레임 body pose parameter는 알고 있다고 가정 shape 파라미터는 사실 의미가 없는게 대충 찾아도 뒤에 3DGS 위치 변화로 커버 가능. |
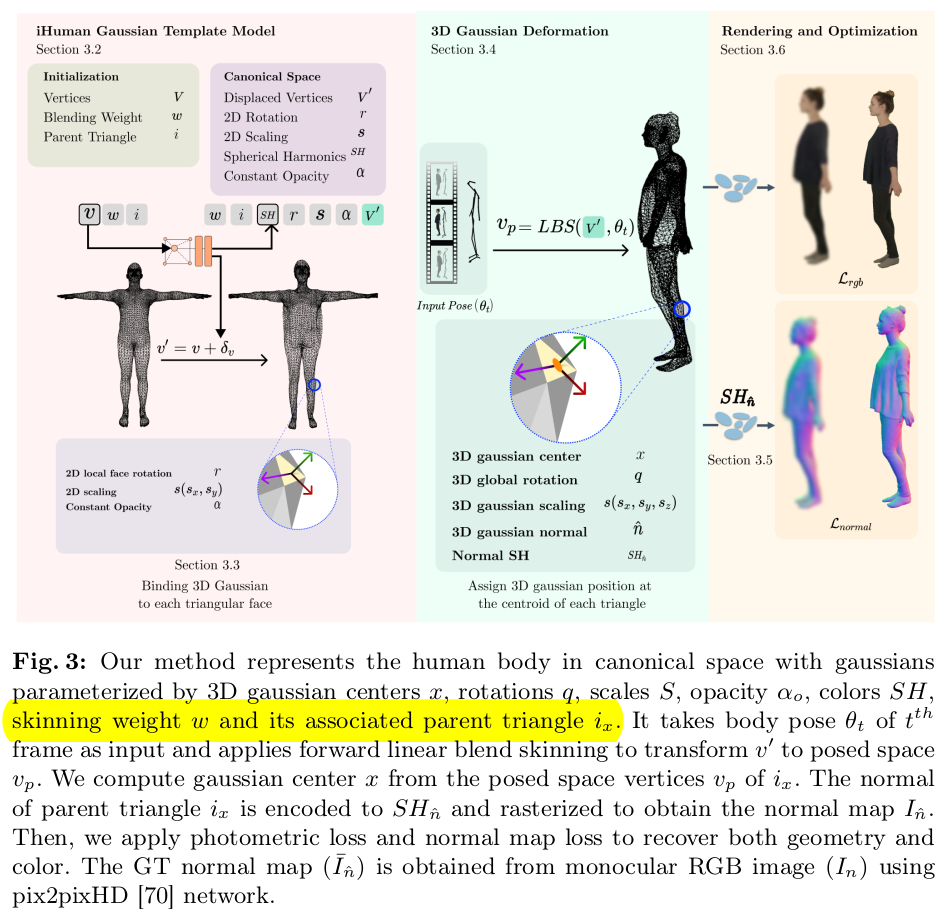 |
그림이 조금 복잡한 듯 하지만 핵심은 맨 왼쪽에 하나 오른쪽에 하나 왼쪽) 3DGS가 skinning weight를 갖고 있음 오른쪽) photometric loss 말고 normal loss를 사용해서 face마다 할당된 3DGS를 더 정확하게 업데이트하는 것. |
  |
3DGS에는 새로운 파라미터 3개가 들어있다. learnable은 skinning weight, vertex 1 2 3 displacement. 원래 있던 3DGS property는 그대로 fixed는 triangle index (어느 face에 속했는지) 3DGS position은 vertex+displacement를 평균내서 찾는다. 결국 vertex displacment만 정확하게 찾음. (한개의 vertex가 여러 face에 속할 수 있으므로 displacement가 여러개 나올 수 있는데 상관없다. x를 찾는 과정에서 vertex+dx를 활용할 뿐이지 실제로 vertex를 움직이는게 아님. 결과물도 3DGS만 꺼내서 씀. 나중에 버려질 값) |
 |
SuGaR에서 착안해서 기존 3DGS property 의 자유도를 2로 낮춤. normal을 계산해서 3DGS covariance matrix 자유도 낮추고 scale도 해당축 1mm로 고정해서 낮춤. |
  |
skinning weight는 (적혀있진 않지만) 3DGS 별로 엮여있는 vertex 3개를 평균내서 초기화했을 듯. 그리고 learnable로 열어둬서 학습했다. SMPL bone transformation matrix는 그대로 사용. |
  |
여기가 진짜 핵심. 3DGS를 학습할 때 photometric loss만 사용하면 잘 안됨. ECON에서 pseudo GT normal이라도 활용하면 좋아진다는 것을 봤기 때문에 여기에서 착안해서 3DGS가 갖고 있는 normal도 supervision에 사용하기로 함. human normal image는 pix2pixHD로 생성 3DGS normal을 집합해서 normal image를 만들어야 하는데 이 때 아이디어가 좋다. SH 값을 이미지로 렌더링하는 코드는 이미 3DGS 코드 안에 구현되어 있으므로, SH 값을 normal로만 바꿔쳐서 렌더링했다. 말그대로 SH 2nd, degree0의 값 3개를 normal로 바꿔서 렌더링한 것이다. 그러면 normal 이미지 얻을 수 있음. differentiable한건 물론) normal supervision으로 인해 성능이 많이 좋아진 듯. |
   |
SMPL는 upsampling해서 vertex 많은 버전으로 사용했고 각 비디오 초기화할 떄는 ReFit을 썼다고 함-> PyMAF랑 거의 비슷한 방식인데 비디오 sequence에 더 유리한 방식이라 정확도가 높음. |
  |
 |
 |
 |
 |
 |
 |
 |
반응형