반응형
내 맘대로 Introduction

이 논문은 임의의 face mesh를 특정 스타일의 mesh로 바꾸고 (e.g. 고블린) 3DMM 파라미터 갖고 변형이 가능하도록 한 논문. general to general 은 아니고 general input to fine-tuned unique styled output 형태다.
핵심 아이디어는 3DMM 갖고 일반적으로 사람 얼굴 형상 변형에 특화된 backbone을 하나 만들어두고, 대상이 정해지면 그 스타일의 mesh만 갖고 input to styled mesh fine tuning하는 방식. 이 때 데이터가 충분하지 않으니 self-supervised + CLIP을 활용한 점.
3DMM을 강하게 사용하는 방법론이다보니, styled mesh 역시 3DMM을 변형한 mesh여야 한다. 즉 topology가 3DMM과 같은 학습 데이터가 있어야 한다. 논문 저자들은 직접 손으로 3DMM을 변형해서 만든 데이터를 갖고 실험했다.
데이터가 풍성했다면 더 다른 시도를 많이 해봤을텐데, 데이터 때문에 고민한게 좀 묻어나는 논문.
메모
 |
|
  |
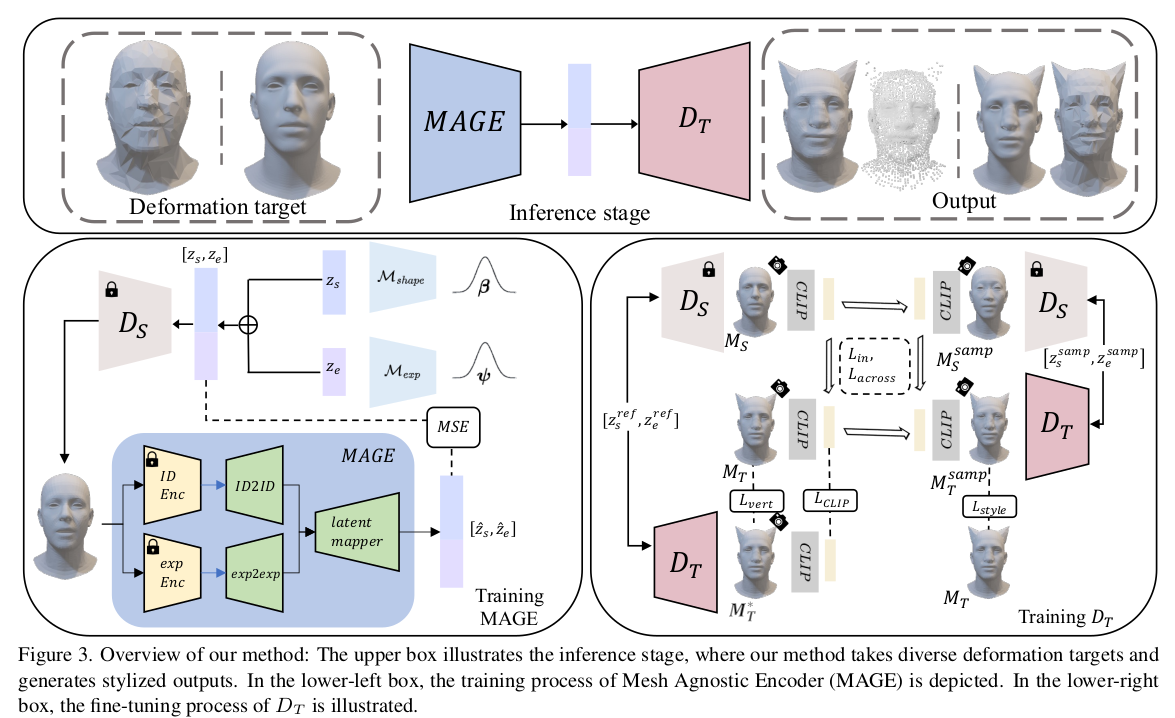
그림이 꽤나 복잡하고 한 눈에 읽히진 않는다만, 그 이유는 MAGE라는 이 내용이 사실 다른 논문에서 뗘온 것이라 생략한 점이 많아서다. 저 ID Enc와 exp Enc는 SIGGRAPH에서 나온 mesh encoder 구조. 임의의 mesh로 부터 exp, id feature를 뽑아주는 네트워크다. MAGE의 ENCODER를 떼어와서 뒤에 3DMM latent를 뽑아내는 뒷부분을 갖다 붙인 것 pretraining 3DMM의 eigenvector를 네트워크화 하는 셈. mesh to latent, latent to mesh 두가지 를 학습한다. 임의의 latent를 샘플링해서 loop를 돌면서 무한히 트레이닝. fine tuning 새로운 decoder 설계. (pretrained copy한거 겠지?) 주어진 pair 1쌍에 대해서만 tuning 이 때 pretrained net과 지속적으로 loss를 걸어주어서 distillation되듯이 fine-tuning이 약간의 generalizatino 능력을 갖추도록 만듦. |
  |
사전학습은 간단하다. 네트워크가 3DMM eigenvalue를 먹고 mesh vertex를 내뱉도록 설계. 직접 l2 loss 3DMM vertex에서만 sampling해서 학습하면 효율이 떨어지니까 subdivision해서 좀 더 dense 하게 sampling. -------------- 개인적으로 논문이 약간 불친절하게 작성되었다고 생각하는 점이 네트워크 구조는 물론, 입출력에 대한 설명이 두루뭉술하게 적혀있어서 논문만 보고 한 번에 뭘어떻게 구현하고 어떻게 학습했구나가 잘 안그려진다. point 개별적으로 처리한건지, transformer로 다 때려넣고 한번에 처리한건지 파악 불가. 사전학습 Ds를 copy해서 Dt를 만든건지도 모름.  supplementary에 구조는 적혀있긴 한데, 본문에 넣어놔야 하지 않을까. supplementary를 보라고 하거나. MAGE가 알고리즘의 시작단계에 해당하는데 논문 맨 끝에 설명되어 있어서 이것도 NFR 모르는 사람이면 어리둥절할 것 같음. |
  |
** 여기서 저 대문자 phi는 어디서 나온건지 모르겠다. 문맥상 z_exp, z_id를 의미하는 것 같긴 하다. 위에서 beta, psi로 쓴 걸 쓰거나, z를 쓰거나 하면 이해하기 편했을 듯. finetuing은 하나의 3DMM like mesh + styled mesh pair가 주어짐. 1) MAGE를 통과시켜 Z_ref 뽑기 2) pretrained network 통과시켜서 mesh 생성 3) 새로운 network 통과시켜서 mesh 생성 4) 2)-3) 간의 CLIP을 활용한 loss로 새로운 네트워크 학습 5) 추가로 임의의 z_sample로부터 2)-3)을 반복해서 비스무리한 mesh pair를 만들고 앞선 ref mesh들하고 간접 비교하는 loss 추가 |
   |
1) vertex reconstruction loss Dt output과 GT styled mesh 직접 비교 2) CLIP reconstruction loss Dt output을 렌더링해서 CLIP으로 압축한 것과 GT styled mesh를 렌더링해서 CLIP으로 압축하는 것 비교 3) CLIP directional loss 주어진 mesh pair 말고 보조용으로 z_sampled에서 만든 mesh pair를 가지고 cross로 2) loss를 맥인 것. (변형을 잘 하도록 학습되었다면 어떤 mesh가 주어지든 대충 비스무리하게 생기게 뱉긴 해야된다는 약한 constraint) |
 |
4) style loss exp, id z중 exp만 ref꺼 쓰고 id 는 sample꺼 써서 하나 mesh vertex를 얻음 (대상은 다른데 표정이 같은 경우로) 대상이 다를지라도 표정이 같기 때문에 normal이 비슷하다고 가정 normal이 갖도록 regularization |
  |
NFR이랑 Diffusion net 읽고 와라. 가져다 썼다. |
 |
 |
 |
 |
 |
|
   |
  |
반응형
'Paper > Human' 카테고리의 다른 글
| iHuman: Instant Animatable Digital Humans From Monocular Videos (0) | 2024.08.20 |
|---|---|
| Neural Face Rigging for Animating and Retargeting Facial Meshes in the Wild (0) | 2024.08.09 |
| Expressive Whole-Body 3D Gaussian Avatar (0) | 2024.08.06 |
| High-Quality Facial Geometry and Appearance Capture at Home (0) | 2024.07.31 |
| High-Quality Passive Facial Performance Capture using Anchor Frames (0) | 2024.07.19 |