반응형
내 맘대로 Introduction
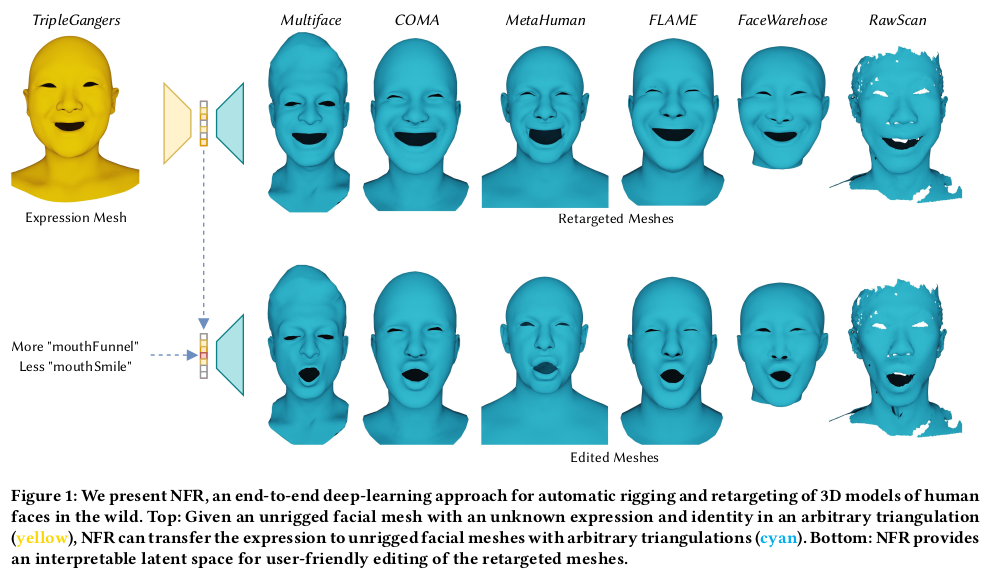
이 논문은 임의의 Face mesh가 들어왔을 때, 3DMM expression mesh를 driving signal로 이용해서 표정을 변화시키는 논문이다. expression feature와 id feature를 뽑아내는 두 개의 encoder, deformation field를 뱉어내는 한개의 decoder로 구성되어 있다.
목적 분명, 구조 깔끔, 방식 깔끔. 되게 좋은 논문이라고 생각한다. 학습을 위해선 3DMM이 fitting된 다양한 표정의 Face mesh가 필요하다.
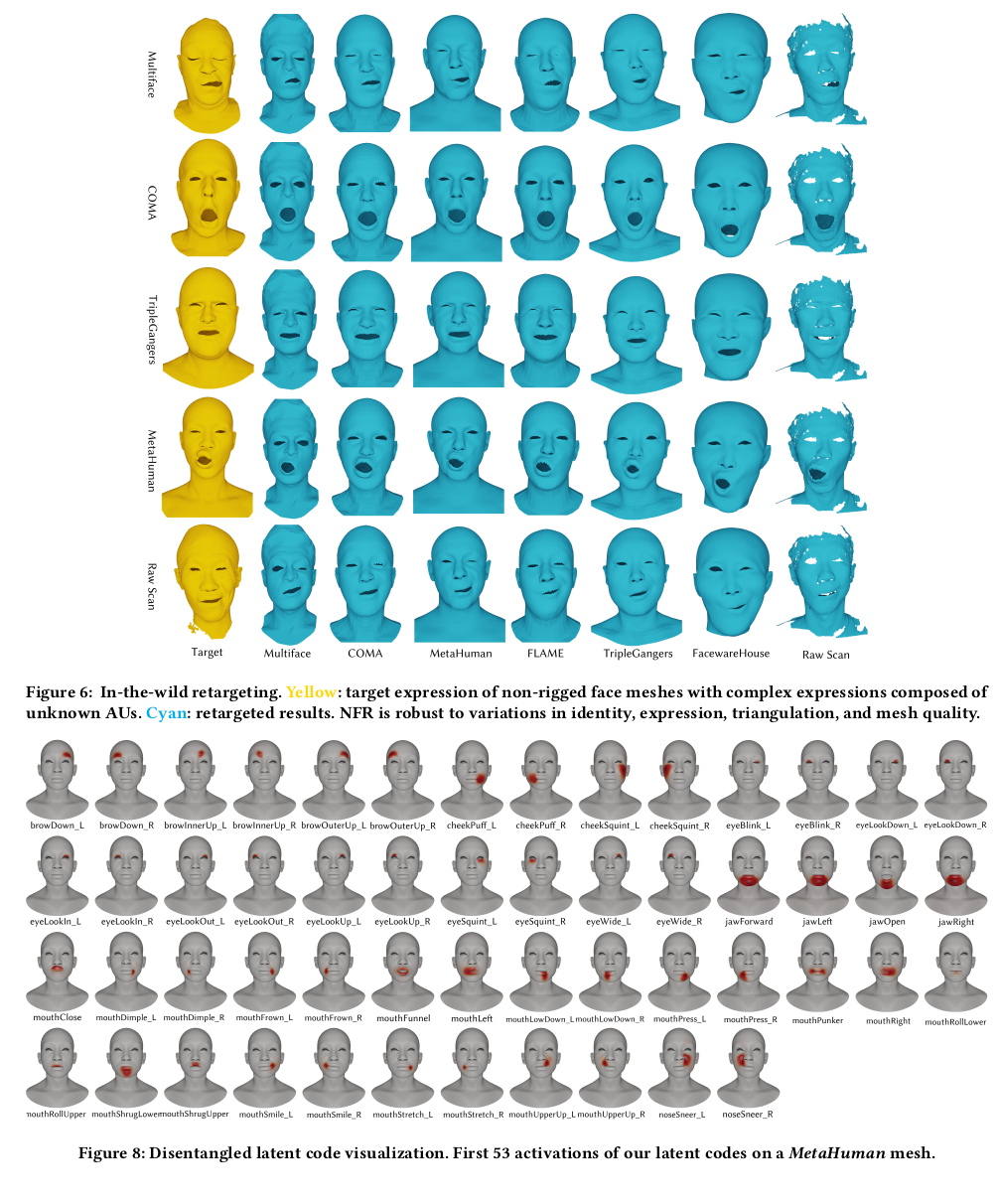
그림도 잘 그려서 보면 바로 이해된다.
메모
 |
|
 |
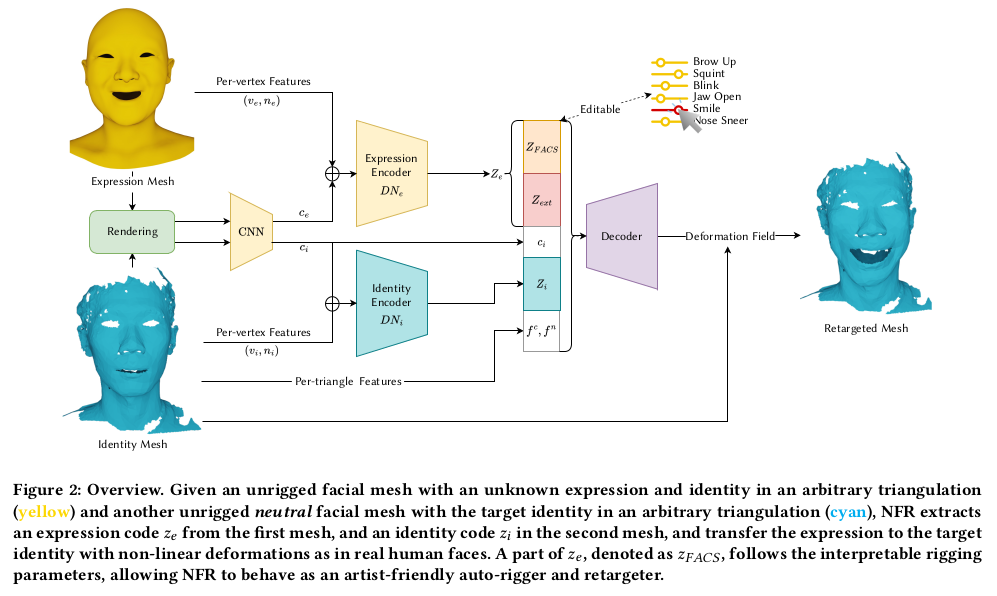
1) id encoder : diffusion net 구조 입력 : 무표정 임의의 mesh 출력 : id latent 2) exp encoder : diffusion net 구조 입력 : 표정있는 3DMM 출력 : exp latent 3) rendered image encoder : CNN 입력 : rendering된 이미지 출력 : img code 128 dimension 4) decoder : NJF (neural jacobian field) 구조 입력 : id latent + exp latent + img code + per triangle feature 출력 : 무표정 임의의 mesh -> 표정있는 임의의 mesh deformation |
 |
1) 2) 구조에 대한 설명인데 diffusion net 가져다 쓴거고 per-vertex feature에 image code 128차원을 더해준 것. 어떻게 더했는지 concat을 한건지 모르지만 그닥 중요하진 않아 보임. expression latent의 경우, 그냥 128차원으로 만들어도 되지만 이왕이면 latent를 보고 무슨 표정인지 해석할 수 있으면 좋으니까 ARKit에서 제공하는 53 latent (내 생각엔 53개 표정 blendshape coefficient 같음) + 75개 latent로 구성했음 초반 53개는 웬만하면 ARKit 값과 같도록 regularization 했음. |
 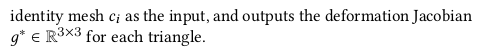 |
** per triangle feuture는 triangle center + normal 임 NJF 는 neural jacobian field 라는 논문으로 mlp인데 위치+normal을 갖고 중간 산출물 gradient를 만들고 이를 같이 활용하는 MLP다. 가져다 쓴 것. |
 |
데이터는 random shift, scale 일부러 삭제하고 구멍 뚫고 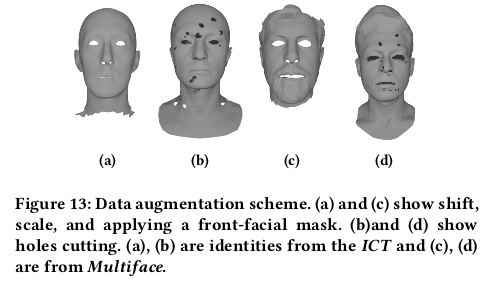 |
  |
기본적으로 mesh <-> fitted template이 있는 구조이므로 vertex level에 직접 supervision gradient 도 직접 supervision normal도 직접 supervision ------------ expression encoder는 출력이 초반 53개는 ARKit과 맞아 떨어지도록 유도할 거니까 초반 53개는 fitted template의 coefficient와 같도록 함. 나머지는 크기 0으로 regularization cofficient없는 데이터들은 그냥 크기나 0~1 안으로 유지 시키는데 활용함. |
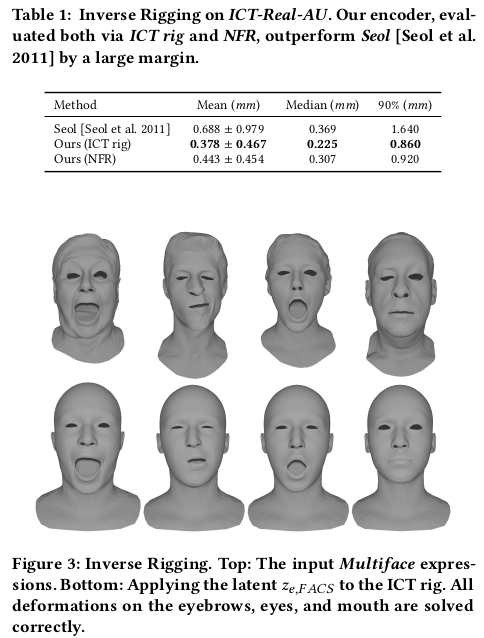 |
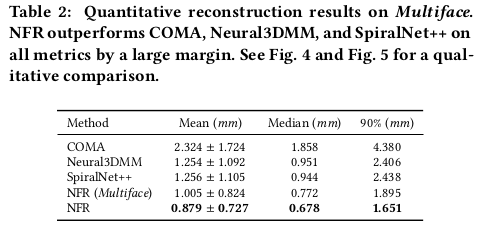  |
 |
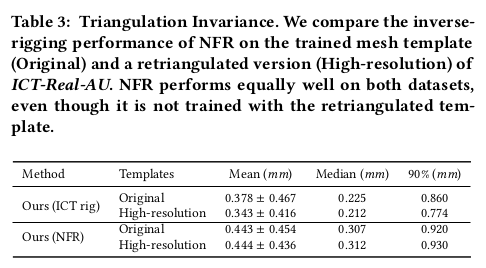 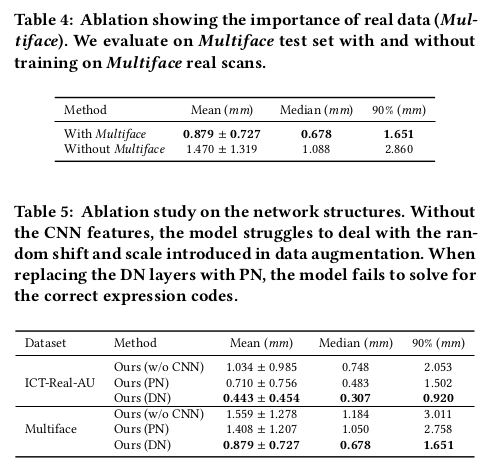 |
 |
 |
반응형
'Paper > Human' 카테고리의 다른 글
| Sapiens: Foundation for Human Vision Models (2) | 2024.08.26 |
|---|---|
| iHuman: Instant Animatable Digital Humans From Monocular Videos (0) | 2024.08.20 |
| LeGO: Leveraging a Surface Deformation Network for Animatable Stylized Face Generation with One Example (0) | 2024.08.09 |
| Expressive Whole-Body 3D Gaussian Avatar (0) | 2024.08.06 |
| High-Quality Facial Geometry and Appearance Capture at Home (0) | 2024.07.31 |