반응형
내 맘대로 Introduction

monocular video로부터 NeRF 컨셉 기반의 implicit animatable head avatar를 만드는 방법. 역시나 표정 변화를 위해 3DMM을 활용했다.
핵심 아이디어는 3DMM expression coefficient 1개 1개마다 voxel basis를 붙여서 3D 공간을 더 잘 표현함과 동시에 3DMM과는 implicit하게 엮여있도록 유지했다는 점이다. 단순한 아이디어이지만 SIGGRAPH 게재 논문이고 속도 개선과 성능 개선이 둘 다 돋보이는 논문.
메모
 |
|
  |
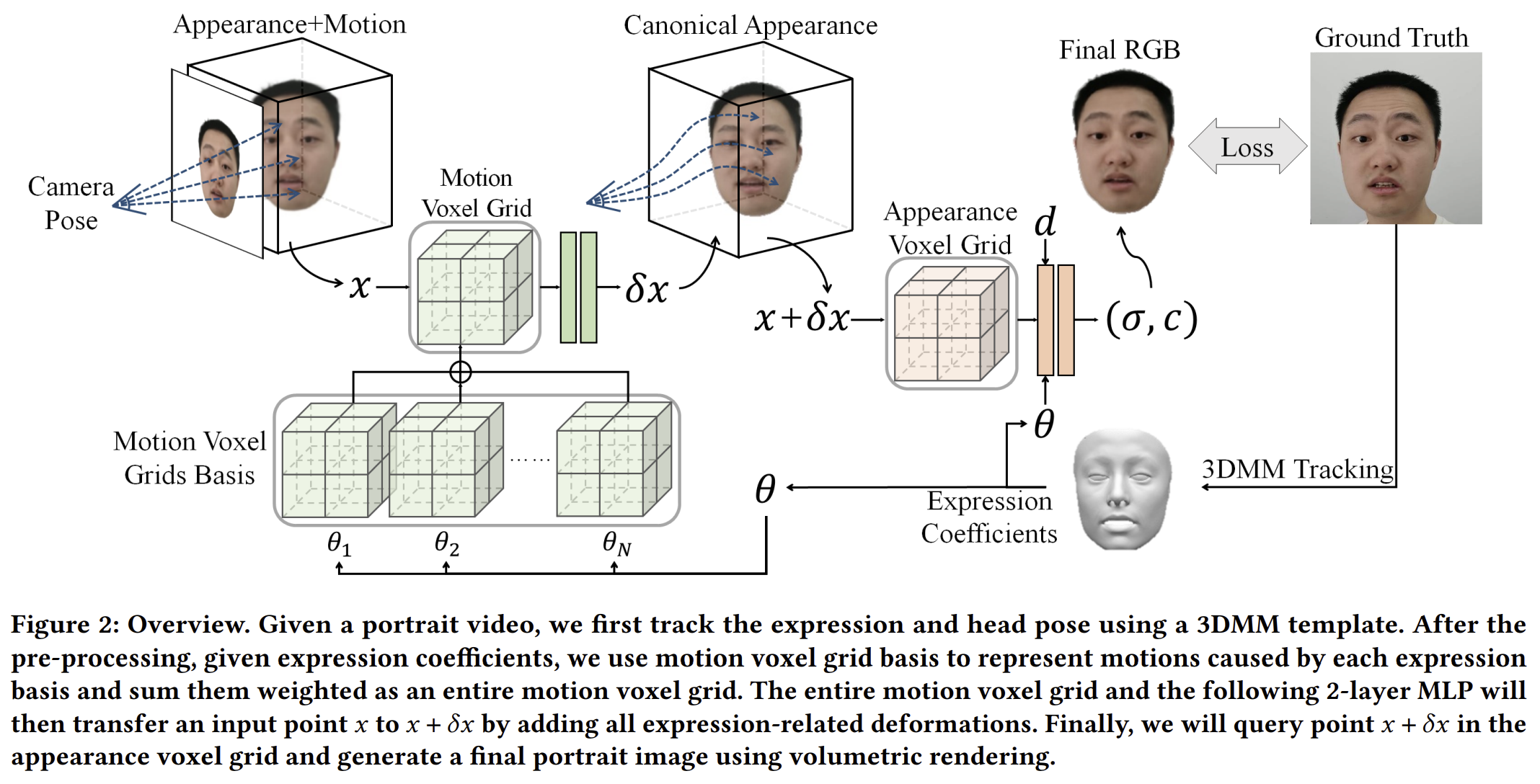
NeRF 컨셉인데 기본 표현 구조는 voxel grid (feature volume)을 사용함. 이는 메모리 사용량과 속도 때문. 1) canonical apperance voxel grid는 1개 따로 만들어 둠 2) expression dependent voxel grid 는 N개 존재 - 각각이 3DMM expression 파라미터 N개를 eigen value처럼 쓰는 basis들 3) expression voxel grid에서 모은 feature를 먹고 deformation field를 구해주는 네트워크가 있고 4) 이를 받아 더한 뒤 canonical appearance 를 표현해주는 기본 네트워크가 있음 |
  |
expression basis들은 3DMM expression 파라미터에 곱해져서 최종 volume feature가 됨. volume feature -> 특정 point feature 로 sampling 하는 방식은 interpolation해서 만듦 trilinear 아니고 multi-distance interpolation 씀 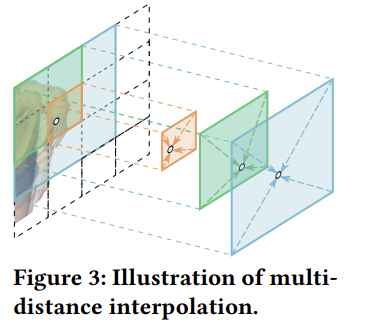 알아보니 위 그림처럼 더 멀리 있는 값들까지 interpolation해오는 방법. nearest, sub-nearest, subsub-nearest interpolation 한 뒤 concat. 이렇게 뽑힌 point feature는 deformation field 출력하는 네트워크 입력이 됨.  3DMM expression에 대응되는 basis를 찾는건 아이디어 좋은 듯. |
 |
canonical appearance 부분은 voxel representation을 쓰는 NeRF랑 완전 동일하나, expression parameter를 컨디션으로 받게만 수정했음. |
 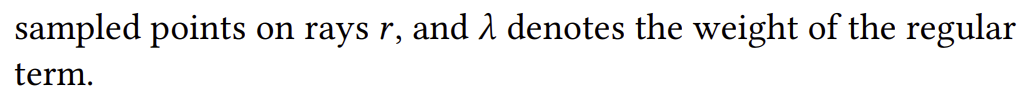 |
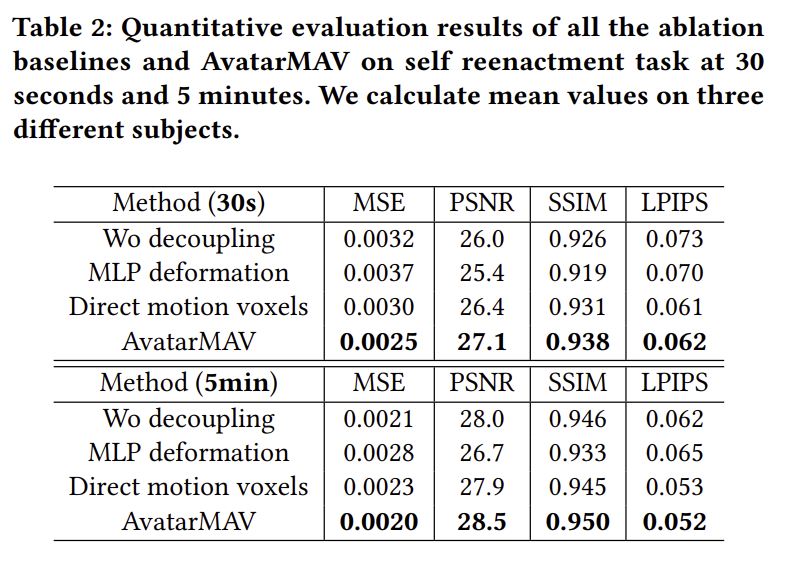
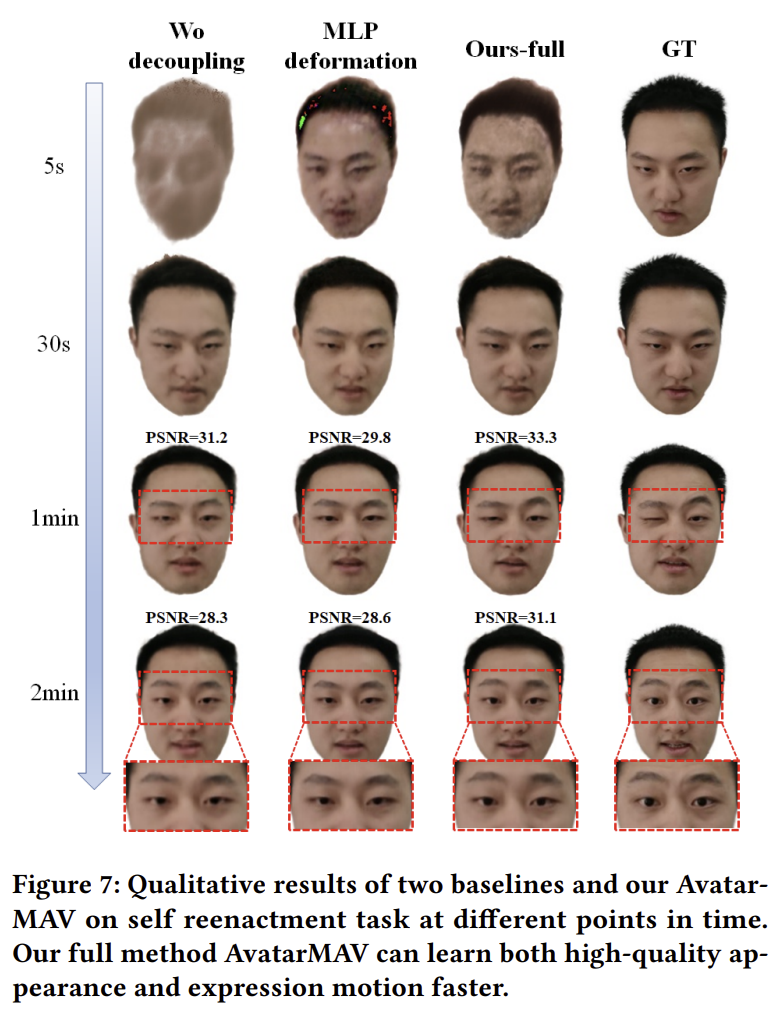
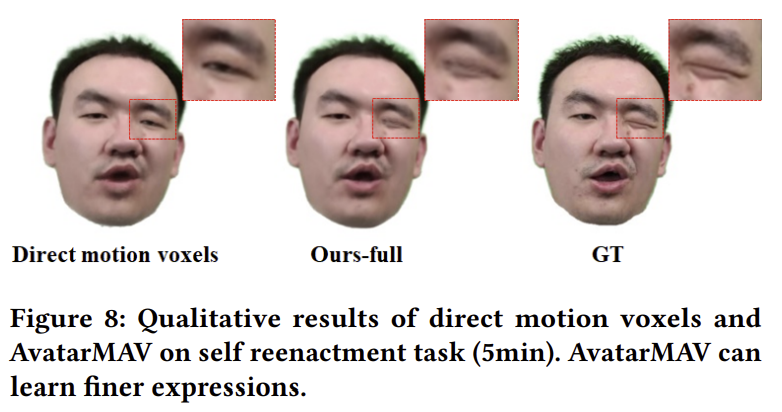
전처리는 facial crop + 3DMM tracking 경험 상 basis 값을 보니, face가 아닌 영역에서 offset이 발생하는 문제가 있었다고 함. 이를 막기 위해서 basis를 0으로 잡아당기는 regularization 추가 rendering loss는 핵심. |
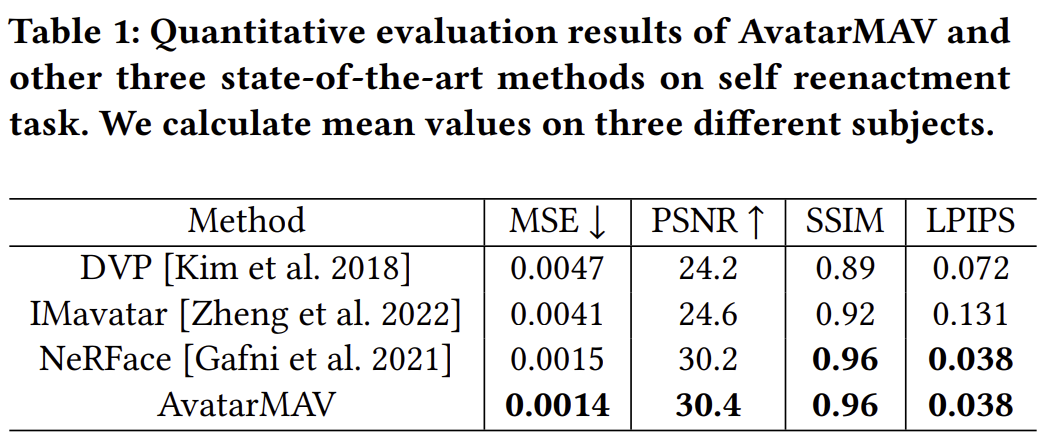 |
 |
 |
|
 |
|
 |
 |
 |
 |
반응형