반응형
내 맘대로 Introduction

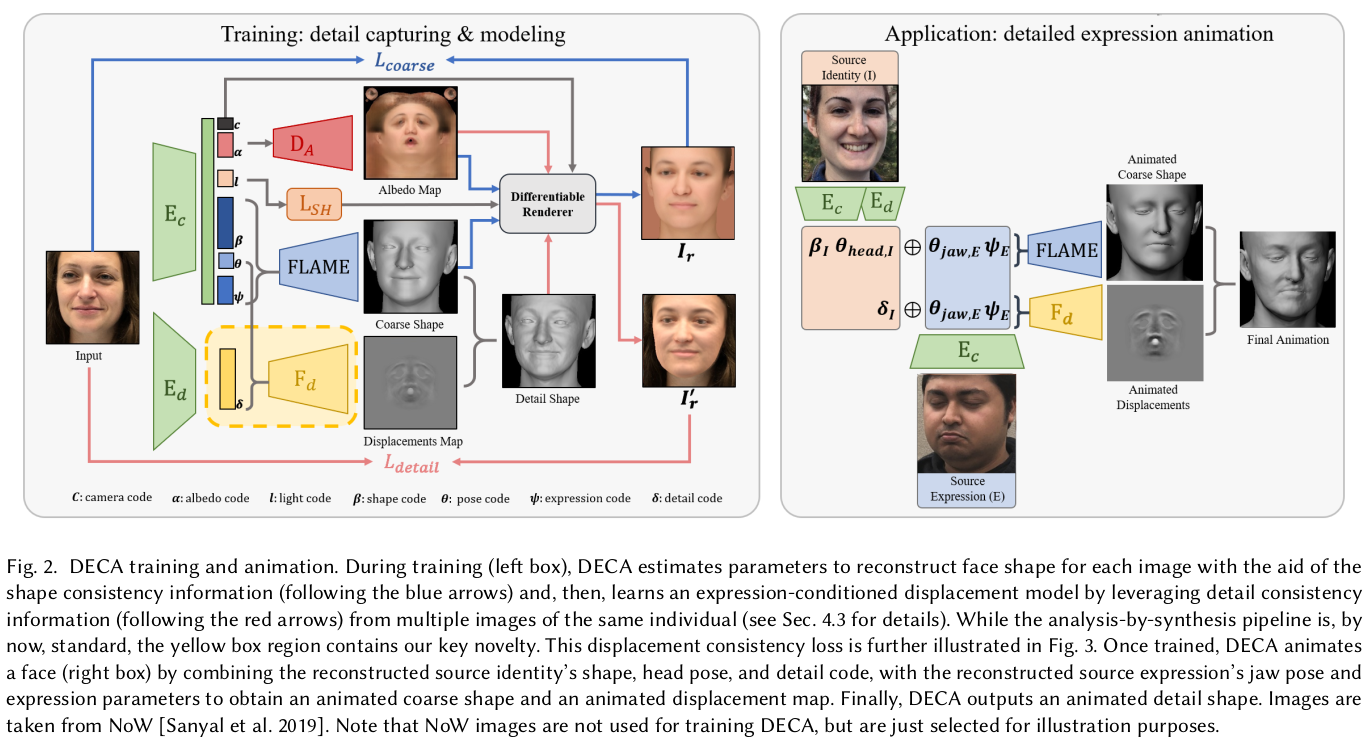
single image to 3d animatable avatar. 일종의 HMR 처럼, 3DMM FLAME 모델 파라미터를 추정하는 backbone인데 In-the-wild 이미지를 학습 데이터로 사용했기 때문에 데이터 양에서 강점이 있다. 더불어 모델 파라미터만 추정하는 것이 아니라, light, albedo, subject-specifi detail (displacement map) 같은 것을 같이 추정하도록 설계한 것이 차이점.
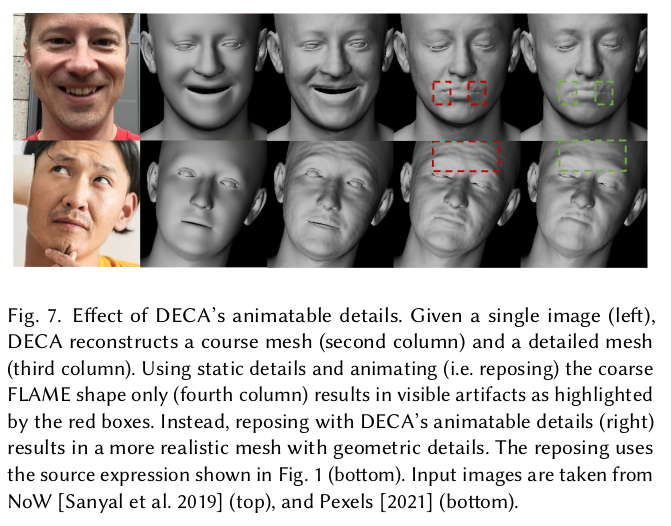
핵심은 3DMM FLAME 파라미터가 미처 표현하지 못하는 subject-specific detail을 추정하도록 네트워크를 설계한 점과, 이 둘이 각각 다른 feature를 사용하도록 분리했다는 점이다. 직관적으로 표정이나 뚱뚱한 정도가 사람마다 미묘하게 다른 디테일과는 다른 영역이기 때문.
직관적으로 생각한 내용을 구조에 잘 반영해서 설계했고 학습도 주어진 데이터에서 효과적으로 잘 한 듯한 논문.
논문 구성이 네트워크 구조/기능 -> 학습 loss 순서대로 단락이 반복된다.
메모
 |
|
 |
핵심 직관은 사람마다 다른 미묘한 차이(e.g. 주름)는 FLAME이 표현할 수 있는 영역 + 표정과는 연관이 크게 없다는 것이다. 따라서 feature level에서도 FLAME 파라미터 추정에 흘러들어가는 것과 face detail 추정에 흘러들어가는 것이 달라야 된다고 생각 대신 face detail도 표정을 알긴 알아야 현 표정 +@를 추정할 수 있기 때문에 FLAME pose/expression parameter만 추가 입력으로 받음. 1) FLAME backbone - camera - light - FLAME 파라미터 2) FACE DETAIL backbone - (FLAME pose/expression parameter 추가입력) - 일종의 depth 추정 (FLAME normal을 곱해서 표면 변화시킴) 3) 다 엮어서 diff.rendering으로 일반 이미지와 비교. |
  |
FLAME backbone - resnet50 사용 - FLAME 파라미터 - camera code - light 추정 총 236 dim. feature를 뱉음 |
 |
FLAME backbone에 사용한 loss 1) face keypoint reprojection error 2) 그중 특히 눈꺼풀 keypoint는 서로 상대거리가 일정하도록 ( 1)과 거의 유사한데 눈이 잘 안감겨서 한 번 더 강조용)  |
   |
3) 당연히 기본이 되는 rendering loss 4) identity loss 이건 사람 얼굴의 identity가 유지되도록 강조하는 기능 - 사전 학습된 face recognition network를 가져와서 perceptual loss처럼 사용함. |
 |
5) shape consistency loss FLAME backbone이 shape parameter를 추정할 때 사람 얼굴을 제대로 보고 있다면 같은 사람의 다른 사진을 넣었을 때 "같은 shape parameter"를 추정해야 한다는 가정  같은 사람 이미지에서 뽑은 shape parameter를 서로 바꿔가면서 렌더링을 했을 때도 렌더링 결과가 변하지 않도록 강조 |
 |
FACE DETAIL backbone은 일종의 depth map을 뽑아줌. - FLAME pose/expression params.와 이미지를 입력으로 받음 - 128 dimension 뽑고 depth map으로 decoding - FLAME normal * depth map으로 최종 face detail displacement map 만듦. - 기존 FLAME mesh vertex 이동 - 새로 렌더링. |
  |
FACE DETAIL backbone에 사용된 loss 1) 기본이 되는 color loss, 새로 렌더링한 결과에 rendering loss 2) ID-MRF loss 사실 상 perceptual loss랑 동일 VGG19 pretrained feature와 FACE DETAIL backbone feature가 유사하도록 특정 layer에서 강제. 3) 사람 얼굴이 대충 대칭이니까 추정된 depth map이 좌우 대칭이길 어느 정도 강제함 4) depth map은 어디까지나 보정용이니 그 범위를 +- 1cm로 제한하고 0에 가깝도록 regularization도 추가. |
 |
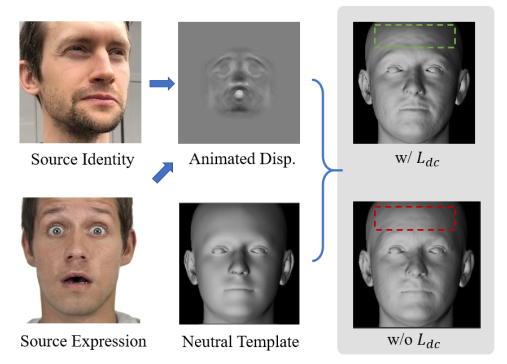
5) shape consistency랑 마찬가지로 face detail도 subject가 같으면 일관되기 유지되어야 하니. 같은 사람의 다른 이미지들을 여럿 모아놓고 서로 face detailed feature만 바꿔가면서 렌더링 했을 때 결과가 안바뀌도록 강제함. |
  |
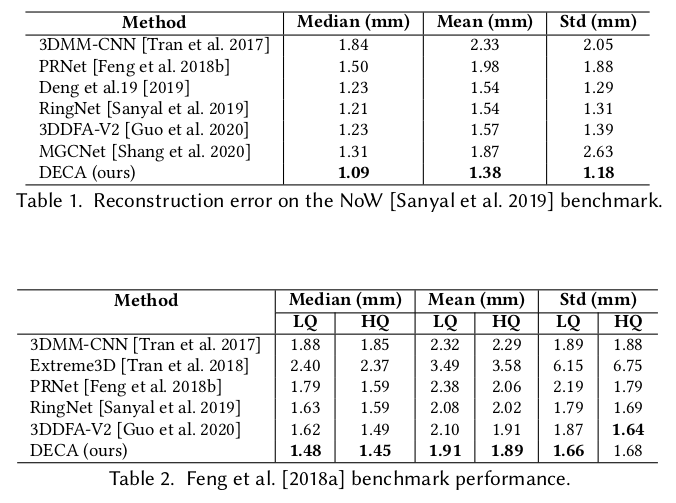
데이터와 사전학습 네트워크 뭐 썼는지 리스트업. |
 |
|
 |
 |
 |
 |
 |
|
 |
 |
반응형