반응형
내 맘대로 Introduction

monocular head video to animatable implicit head avatar. 같은 문제를 푸는 논문이 워낙 많아서 입력, 출력은 여느 논문과 같다. 이 논문은 비교적 나온지 오래된 논문이고 InstantNGP랑 같은 원리로 가속했고, 3DMM expression parameter를 컨디션으로 주었다.
핵심 아이디어는 역시나 expression parameter를 컨디션으로 주고 deformation field를 계한 뒤, 알짜 학습은 canonical space에서만 한다는 것. 그리고 grid hasing을 이용해 가속했다는 점.
참고 포인트는 deformation field를 "예측"한 것이 아니라 3DMM tracking 결과를 이용해서 face to face SE3 transformation matrix를 사용했다는 점.
메모
 |
|
  입력은 1) intrinsic 2) FLAME mesh (with exp., pose.) |
 완전 NeRF랑 동일함. positional encoding만 cos,sin으로 안하고 SH(4) 사용함. |
  |
deformed -> canonical은 네트워크 예측이 아니라 FLAME tracking 결과를 갖고 nearest face to face SE3를 사용한다. 계산 방식은 Frenet frame 어쩌구라고 적혀있는데 이건 그냥 normal, tangent, bitangent 총 3개의 축으로 평면 좌표계를 표현한 것임. 그냥 face to face 같은 축 정의를 통해 SE3 계산했다는 뜻. R은 축간의 SO3 구하고 t 는 vertex 중 1개 간의 translation을 사용했다고 함. (translation 시 왜 평균을 안썼는지는 의문, 그냥 face가 충분히 작아서 그랬나봄) SE3가 구해지고 나면 deform to canonical은 아주 간단. SE3가 face의 크기 변화는 잘 표현하지 못하니 면적 변화를 반영해주기 위해서 scaling 추가 ----------- point - face 하나씩만 풀면 noise가 낄 수있으니 point-face-edge 맞닿은 인접 face까지 보고 가중 평균내서 사용함. |
  |
여기서 point - nearest face search가 시간을 좀 잡아먹는데 이건 bounding volume hierarchy 를 사용해서 줄임.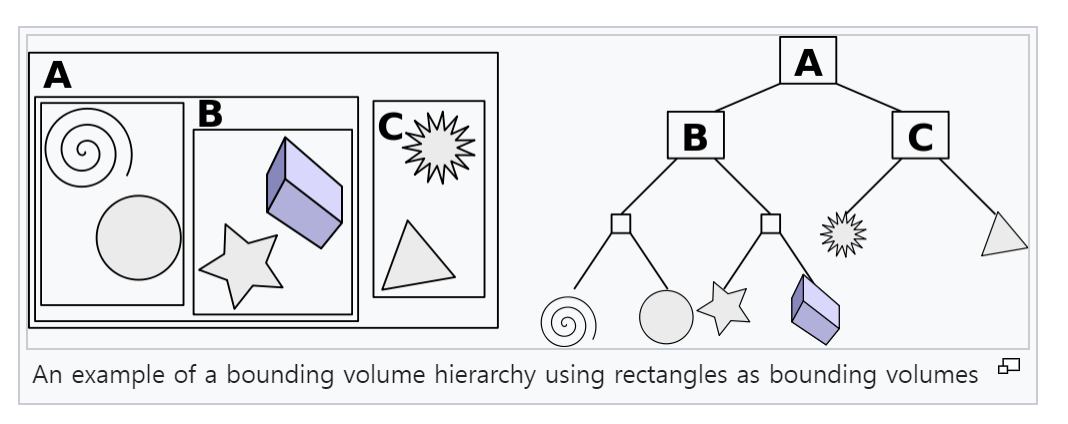 이는 구현적으로 어느 voxel이 어느 local volume에 속했고, 그 local volume은 또 어떤 더 큰 local volume에 속해있는지 미리 tree 구조로 표현해둠으로써 탐색 시간을 줄이는 트릭. |
 rendering loss는 역시나 핵심, 그냥 l2 도 쓰고 huber loss도 씀. |
 depth loss도 도움이 되었다고 함. 3DMM tracking 결과로부터 만든 depth와 rendered depth가 유사하도록. (얼굴 geometry를 벗어나지 않도록) 다만 머리카락 부분은 이런 가정이 방해될 수 있으므로 face 영역만 한정. |
  |
속도 향상을 위해 NGP 사용. |
 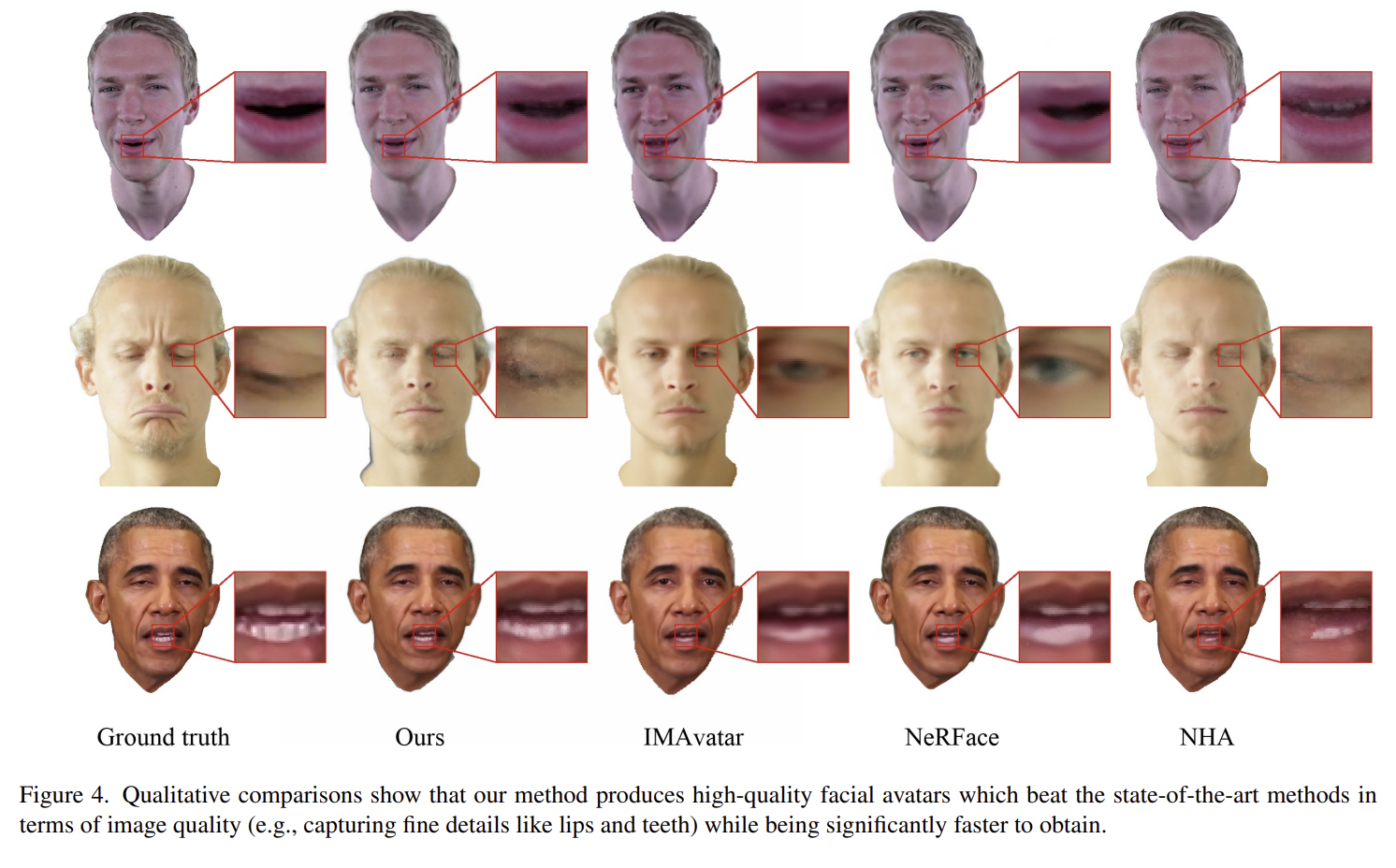 |
|
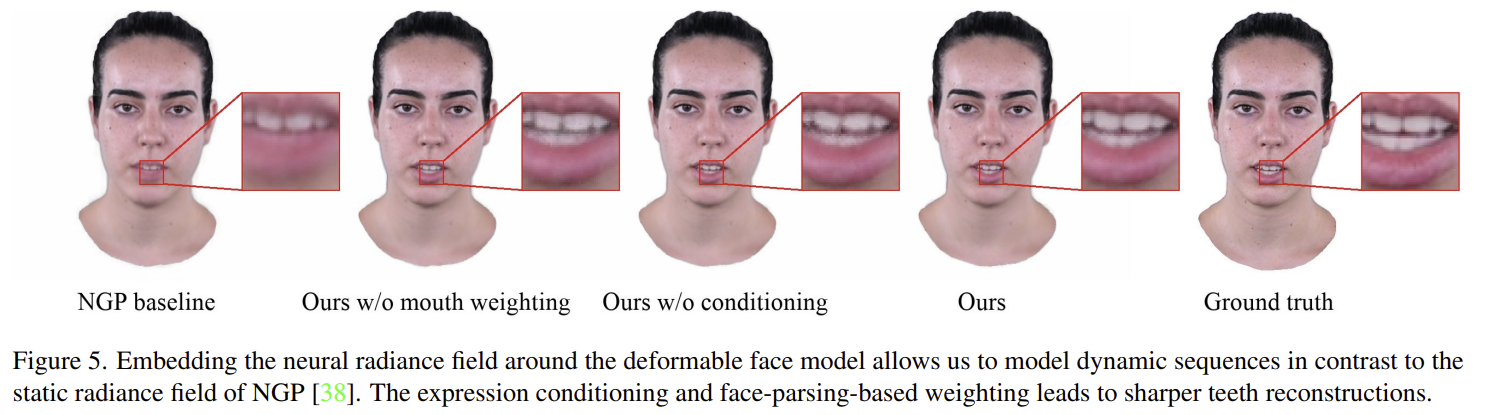 |
|
 |
  |
 |
 |
반응형