반응형
내 맘대로 Introduction

Meta에서 낸 3D gaussian 활용 논문인데 결과가 압도적이다. 머리카락, 안구, 피부결까지 보일 정도로 고해상도 아바타를 만들어낼 수 있는 기술이다. 다만, 110대의 DSLR으로 촬영한 이미지들이 있어야만 하고 사람마다 학습을 따로 따로 해야하기 때문에 범용성에서는 아쉬운 점이 있다. 하지만 촬영 대상에 한해서는 여느 알고리즘과도 비교할 수 없을 정도로 정밀한 렌더링 결과를 보여준다. 심지어 촬영 때 calibrated light source까지 바꿔가면서 촬영했기 때문에 빛 변화도 같이 렌더링할 수 있다.
핵심 아이디어는 기존 머리 모델 (+안구 모델)의 texel 하나하나에 3d gaussian을 할당하고 VAE를 학습시키는 것이다. VAE로 만든 latent code들은 gaze, expression, view angle 같은 값들을 encoding하고 있는데 이 latent code가 바뀔 때마다 3d gaussian의 파라미터들도 바뀌도록 학습했다.
큰 아이디어는 간단하지만 부분마다 디테일들이 상당한 수준으로 녹아있어서 결코 쉽진 않은 논문 같다. 결과를 만들어내기 위해 이것저것 시도해본 티가 팍팍 나는 완성도 높은 논문이다.
메모하며 읽기
 |
|
 |
일단 데이터는 직접 취득해서 사용했다. 그럴 수 밖에 없는 것이 이미지 수를 확보하는 것부터 빛, 표정까지 충분히 확보하는 것이 불가능하기 때문이다. 110개의 카메라 460 LED 조명이 설치된 장비로 촬영했다. 머리 자세나 안구 자세는 기존 알고리즘들 가져와서 풀었다고 한다. |
  |
여기는 3d gaussian recap color dimension이 3인 건 잘못 적은 것 같기도. 뒤에 보면 diffuse랑 specular를 나눠서 다루고, Spherical harmonic, spherical gaussian을 쓰기 때문에 3차원은 아니다. |
 |
차이점은 빛을 반영한 렌더링을 목표로 하기 때문에 color를 빛에 맞게 변화시킬 수 있도록 모델링해야 한다는 점 그리고 표정에 따라 3d gaussian 위치가 바뀌어야 하니 dynamic 요소가 추가되어야 한다는 점이다. |
 |
일단 2D로 처리하기 위해 head mesh UV map texel에 3d gaussian을 하나씩 할당하고 시작한다. 그리고 UV map 레벨에서 모든 작업을 진행한다. (latent code도 H, W C 갖고 있지 않을까) ------------- 따라서 light, dynamic 요소를 추가하기 위해 3D GS parameter를 직접 얻어내는 것이 아니라 VAE decoder가 3d gs parameter를 뱉어내게 만들었다. 즉 쉽게 말하면 정적으로 3D GS parameter 1개를 학습하는 것이 아니라 3D GS parameter space를 학습시킨 것이다. 이 space 안에는 light 건 표정이건 다 포함되어있을 테니 말이다. 빛, 표정에 따라 많은 이미지는 이미 촬영해두었으니, VAE를 이용해 latent space를 구성하는 것은 굉장히 쉬운 일이고 latent code를 바꾸면 빛이든 표정이든 원하는대로 바꿀 수 있도록 설정했다. 구체적으로 decoder(latent code) => position movement, rotation, scale, opacity를 뱉어내도록 했다. **decoder 는 CNN임 |
 |
추가적으로 decoder Dv를 하나 더 두었는데, 같은 latent code로부터 head mesh model vertex를 얻을 수 있게 학습했다. 그 이유은 첫번째 decoder Dg 한테 position자체를 내뱉게 하면 학습 효율이 떨어져서 residual을 뱉도록 해야 하므로 초기 위치를 잡아주는 역할이 필요했기 때문이다. V'를 barycentric interpolation해서 tk를 만든다 |
  |
realistic color를 만들어 내기 위해서 그냥 RGB를 찾거나 SH coefficient 찾는 것을 넘어 diffuse color와 specular color를 분리해서 찾는 방식을 제안한다. 빛을 같이 다루기 때문에 이런 부분에서 더 디테일한 모델링이 필요했기 때문이라고 생각한다. 전방향으로 퍼져나가는 (view independent) diffuse color, 특정 방향으로 튕겨져나가는 (view dependent) specular color로 구성되어 있다. |
 |
diffuse term는 SH로 모델링되어 있다. view independnet라면서 왜 SH로 했느냐? 라고 묻는다면, diffuse color도 빛이 어느 방향에서 "들어오는지"는 중요하다. 빛이 측면에서 들어오는지 정면에서 들어오는지에 따라 diffuse 정도가 달라지기 때문이다. view independent하다는 것은 "퍼져나가는 빛"이 방향에 상관없다는 것이다. 수식(5)를 보면 w_in만 있고 w_out 없는 것을 볼 수 있다. 수식(5)의 경우, 유명한 diffuse color 수식인데 여기서 L()은 알고 있는 것이고 rho_k와 d_k가 모르는 값이다. decoder가 2d latent map을 입력으로 받아 각 pixel의 albedo와 SH coefficient를 찾는 것이다. **SH degree를 얼마까지 써야 좋냐도 하나의 이슈인데, 많이 쓸수록 저장 메모리가 늘어나서 성능과 trade-off가 있다. 저자들은 일단 degree 3쓰고 4~8을 더 쓰되 monochrome으로 썼다고 한다. 3채널 아니고 1채널만 그림자를 표현하는 기능이라도 보조 받도록. |
  |
specular term는 spherical gaussian으로 모델링되어 있다. SG가 뭔지 모르면 Spherical gaussian 참고 수식을 약간 다르게 썼다고는 하는데 이건 실험적으로 실패하는 경우가 많아 변경했다고 한다. 그러나 결국 의미는 같다. 수식(6)을 이용하면 튕겨나오는 빛을 현재 위치에서 관찰했을 때 intensity를 알 수 있다. specular color는 수식(8)과 같이 기존 방식 그대로 계산하면 된다. decoder가 2d latent map(view direction code 포함)을 입력으로 받아 각 pixel마다 현재 비추어진 빛에 대한 반사광 intensity를 얻게 된다. ------------- 왜 diffuse든 specular든 왜 3채널이 아니라 1채널, intensity만 계산하느냐? albedo를 따로 찾기 때문이다 color = albedo*(diffuse + specular intensity) |
 |
위와 같이 color 표현을 모델링하는 것이 효과적이었지만 머리가 대상이다보니 머리카락 부분에서 이슈가 있었나보다. (정확히는 모르겠지만) 머리카락을 축으로 회전하는 방향 ( 대충 사람 머리카락을 위에서 아래로 떨어지도록 되어있으니 사람을 수평으로 뱅글뱅글 돌면서 관찰할 때라고 봐도 될듯)으로 관찰할 때 artifact가 생겼나보다. 이를 해결하기 위해서 specular term 계산할 때 사용하던 normal vector를 gaussian에서 계산해서 쓰는것이 아니라 (어떻게 계산할 수 있는지도 사실 모름) 네트워크가 내뱉는 값을 쓰도록 했다. 그래서 머리카락 부분의 경우 네트워크가 그럴듯한 값으로 보정해서 내뱉도록 했다. |
 |
결론적으로 latent code를 입력으로 받는 decoder는 각각 다음 값들을 내뱉는다. 1) diffuse SH (w/ 4 more monochrome coeffs), opacity 2) view conditioned normal (specially for hair), prior vertex position |
  |
마지막으로 눈알이다. 눈알은 각막이 반짝거리고 반사재질이기 때문에 모델링하기가 너무 어렵다. 따라서 explicit eye model을 따로 가져와서 사용했다고 한다. head mesh 쓰는 것 처럼 반지름, optical axis와 눈알 중심간의 offset, 머리 중심과 눈알 중심간의 offset 총 4개로 표현되는 모델인 것 같다. 이 눈알 mesh model을 (68) 논문 기술을 이용해 대충 현 데이터에맞도록 초기화해주고 이걸 깔고 시작했다고 한다. |
 |
눈알은 근데 head mesh 쓰는 것처럼 쓰면 조금 망가지는 부분이 있었다고 한다. 반짝이는 재질이라는 특징 때문에 촬영 장비에 설치된 조명이 눈에 비쳤을 것이고 이게 discrete하게 460개만 존재했기 때문에 일종의 overfitting이 발생해서 복원 성능이 떨어졌나보다. 그래서 눈에 한정해서는 normal을 추정한 것을 쓰지 않고 모델 noraml을 그대로 썼다. (눈알은 변할리가 없으니까 이게 맞는 듯) 눈알 3d gaussian은 위치도 고정. 추가적으로 각막이 반투명한 특징도 있으므로 color 표현력을 더 열어주기 위해 눈알에 한해서는 diffuse term에서 나오는 albedo를 ivew depedent 형태로 변경했다. 눈알용 decoder도 따로 두었고 수식(10)과 같다. |
  |
머리, 눈알, diffse, specular 등 여러 요소들을 디자인한대로 loss가 추가되어 왔는데 이 모든 것을 다 붙여서 한번에 학습시켰다. (오...) L_rec는 3d gs 쓰니까 color, ssim loss + VAE 복원 전후 vertex mm error L_KL은 VAE다 보니 latent space가 정규분포가 되도록 유지 L_reg 는 1) scale이 너무 작거나 크지 않도록 2) negative color 없도록 3) 눈알 크기 너무 크지 않도록 4) 눈알이 너무 투명하지 않도록 5) 눈알이 visibility가 높도록 (눈알뒤집히는거 막는 term인 듯) |
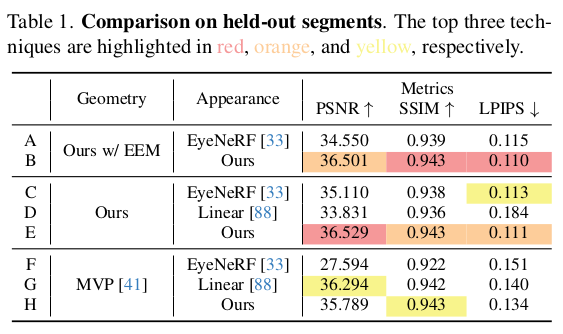 |
 |
 |
 |
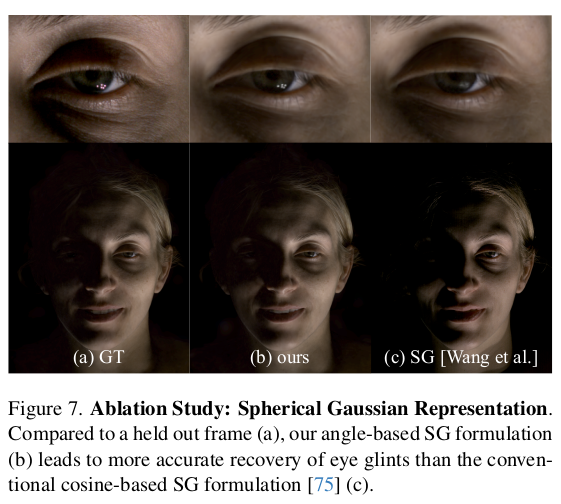  |
 |
반응형