반응형
내 맘대로 Introduction

이 논문은 InstantNGP를 SDF based NeRF에 확장한 논문이다. 복원 대상을 사람으로 한정해서 non-rigid motion을 추가했다는 contribution이 있지만 핵심은 SDF base NeRF의 속도를 비약적으로 끌어올리는 것에 있다.
메모하며 읽기
 |
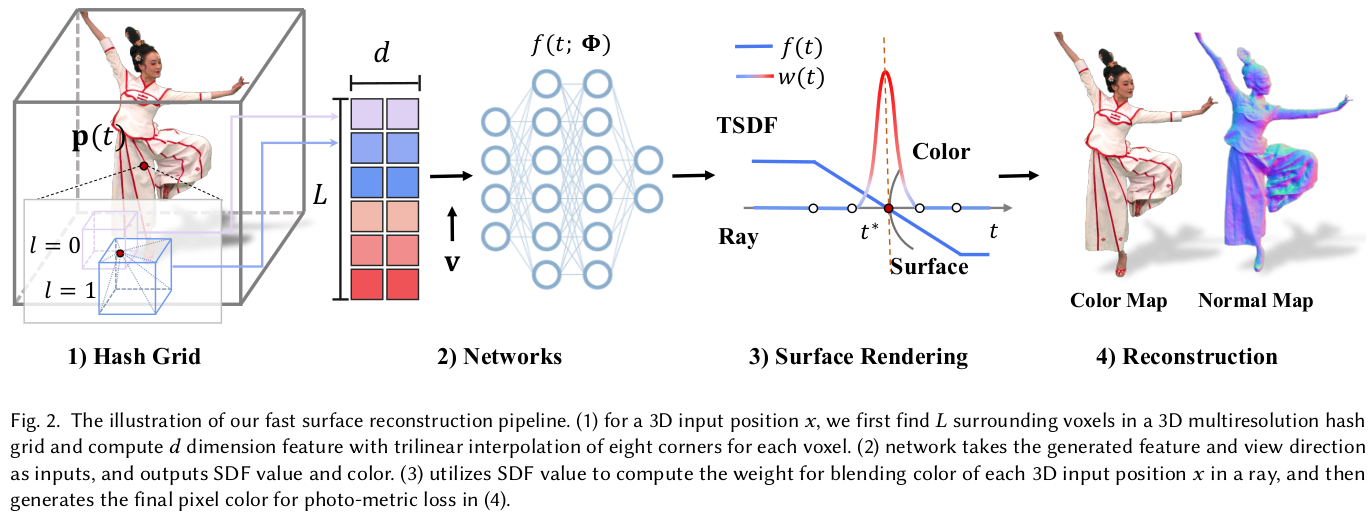
이론적 기반은 NeuS를 그대로 사용했음. |
 |
|
    |
 길고 길게 써있지만 Hash grid를 이용한 SDF 학습을 위해 2nd order derivative 계산 방법을 CUDA로 직접 구현했다는 이야기. 부수적으로 구현을 했더니 SDF는 학습 안정성이 떨어져서 sigmoid를 씌워서 TSDF로 사용했다. 2nd order derivate가 핵심인데 이건 설명보다 구현적인 것이라 논문에 기재되어 있지 않음. 근데 이걸 빼고는 논문 내용이 부족하지 non-rigid 파트를 추가하고 집중 설명한 듯. |
 |
|
   |
 기존 canonical space를 정의해서 쓰는 건 동일하며, 딥러닝 아니고 non-rigid tracking 최적화 기반 방법 그대로 썼음. 첫 프레임에서 복원하고 mesh화한 뒤, embedding deformation node를 지정함 (geodesic distance 따져서 고르게). 그리고 ED 마다 SE3를 추정한 뒤, LBS처럼 neighbor vertex까지 ED의 SE3로 transformation하여 error를 평가하는 식으로 최적화 첫 프레임만 고정적으로 사용하면 large motion에 대해 성능이 떨어지므로 첫 프레임 이후로는 인접 프레임을 사용함. 사용한 loss들은 수식(11) (12)와 같음. |
  |
non rigid tracking 으로 완벽히 커버할 수 있는 건 network로 한 번 더 보정함. Vanilla NeRF를 InstantNGP로 빠르게 학습시키고 고정해둔 뒤, deformation network로 인해 최종 보정된 값을 던져주었을 때 color가 제대로 나오는지를 loss로 걸어주는 식으로 학습을 시킨다. (NeRF를 학습시켜두는 시간도 포함되기 때문에 결국 세가지 네트워크를 쓰는셈이 된다. SDF NeRF, deformation, NeRF)   |
 |
|
  |
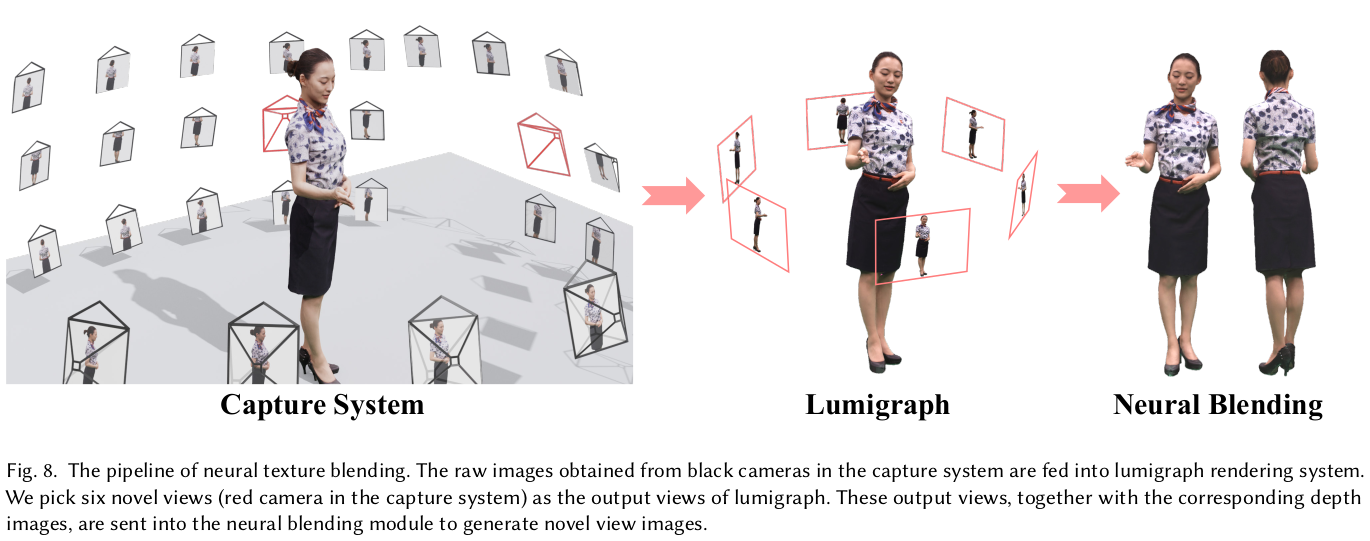
rendering할 때 color를 SDF NeRF에서 나오는 color를 써도 되지만 이럴 경우 색깔 저장해야되는 양이 너무 많기 때문에 효율이 떨어진다. 이를 효율적으로 풀고 퀄리티도 올리고자 image based rendering을 쓴다. occlusion 문제가 없도록 고른 방향에서 6시점 이미지를 생성해두고 geometry를 가지고 어디서 어떤 pixel의 색깔을 뗘와야하는지 계산해서 채우는 식이다. 이럴 경우, 이미지 6장만 저장하면 된다. |
   |
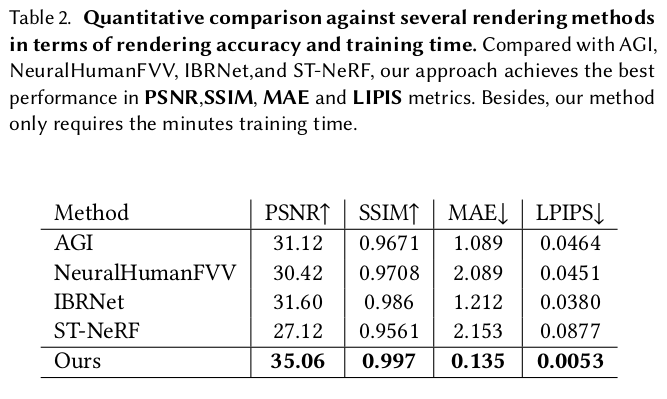
 image based rendering이 미흡한 부분은 역시나 네트워크로 채웠다. 대표적으로 self occlued region이 시점을 6개만 써서 커버가 안될 때다. occlusion이 있다 없다는 일단 네트워크에게 알려줘야 하기 때문에 특정 시점에서 rgbd rendering을 하고 카메라 포즈를 이용해 warping 한다. 그리고 warped depth와 해당 시점 raw depth와 차이를 계산해서 occlusion score처러 쓴다. O color를 보정하는 네트워크, blending network는 각종 시점 rendering 결과와 occlusion score를 입력으로 받고 출력으로 타겟 시점의 color를 어떤 시점에서 얼만큼 가져와야 하는지 blending weight를 내뱉는다. 결과적으로 수식(15)와 같이 각종 시점에서 warped image를 weighted sum하면 현 타겟 시점의 color가 나오는 것. 여기서 입력이 되는 rgb rendering들은 위 image base rendering을 거친 결과들이다. |
 |
|
 |
 |
 |
 |
 |
 |
반응형