반응형
내 맘대로 Introduction

이 논문은 Adobe research 과제로 나온 논문 같은데 왠지 곧 CVPR에 나올 것 같다. 하고자 하는 것은 head mesh model +3d gaussian splatting을 합쳐서 animatable head rendering을 가능하도록 만드는 것이다. 머리를 제외한 대부분 형상(배경, 몸 등)이 고정되어 있다는 전제하에 머리를 가누거나 돌리는 이미지 렌더링을 할 수 있다.
핵심 아이디어는 특별하진 않은데, FLAME이라는 head mesh model vertex를 시작으로 densification하는 것 + vertex prior를 이용해 regularization을 가하는 방식이다. 가장 심플하게 생각할 수 있느 아이디어라고 생각하는데 가장 빠르게 구현한 것에 의미가 있어 보인다. 그리고 일단 결과물이 퀄리티가 좋은 편이다.
메모하며 읽기
 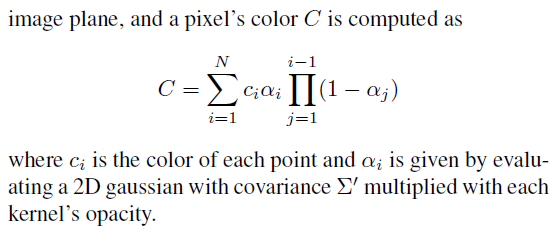 |
recap은 스킵 |
 |
|
  |
1) 촬영된 이미지 COLMAP 돌림 (사람 웬만해선 안 움직인 영상), canonical space 구성. 2) 머리 부분만 align 맞춰서 FLAME vertex 추가 3) FLAME vertex에 가까운 point들만 FLAME vertex와의 거리를 기반으로 regularization 가하면서 deformation space 구성 4) 렌더링 |
  |
1) 초기화에 사용되는 point는 COLMAP + head align한 FLAME vertex다. (어떻게 align 했는지 안 나와있음) ---- FLAME을 prior로 사용하는 가장 쉬운 방식은 3d gs들이 flame vertex에 binding된 형태로 움직이게 하는 것이므로, nearest vertex가 이 논문의 핵심이다. ---- 모든 deformable 논문들이 그렇듯, 초기화 결과가 canonical space가 되고, 그 이외는 deformation space로 정의된다. canonical to deformation 사이의 움직임을 point 단위로 residual로 계산된다. ---- vertex의 nearest point들은 vertex 움직임에만 의존해서 weighted average로 움직인다. |
 |
nearest에 해당하지 않는 녀석들(배경, 몸 등)은 weight를 0으로 만들면 자연스럽게 도태되므로, 굳이 분리할 필욘없다. ---- 실제로는 근데 배경이야 고정되어 있다 쳐도 몸은 촬영할 때 움직일 수 있다. 몸이 움직이면 당연히 연결된 머리도 global하게 움직일 수 있다. 이 global 흔들림을 보정하기 위해서 추가로 displacement 를 추정한다. 그냥 통으로 global displacement를 예측하는 것은 아니고, 이 또한 vertex dependent 형태로 1개, 진짜 global 1개 로 나누어서 추정한다. (왜 굳이 나눴는지는 실험적으로 안돼서 나눴겠지 싶다.) --- inverse distance weighted average는 1) 거리가 먼데 변화가 큼 -> 작게 반영되게 2) 거리가 가까운데 변화가 작음 -> 크게 반영 미세한 변화에 대응할 수 있도록 설계하기 위함이다. |
 |
1) 3d gs deformation 이 vertex deformation과 최대한 유사할 것. (종속 될것) 2) deformation 자체는 일단 작을 것 3) global displacement(흔들림)는 최소가 되게 할 것. |
   |
deformation space가 x,y,z movement만 있으면 안되고 3D GS다 보니 rotation, scale도 당연히 있어야 한다. 이 또한 x,y,z movement 추정한것과 같은 입력으로 rotation, scale residual을 추정하는 네트워크를 붙여서 해결한다. nearest 개념도 다 똑같다. 중간 kabsh 알고리즘은 point 두 군집이 주어졌을 때 두 군집 사이의 상대 R를 계산해는 알고리즘이다. ---- rotation은 최대한 identity에 가깝게, scale은 1에 가깝게 억제한다. ( 결국 촬영할 때 웬만하면 가만히 있으란 소리 아니냐?.. ) |
 |
loss는 전체를 한 번에 사용함. 부분 격파 없음. |
 |
 |
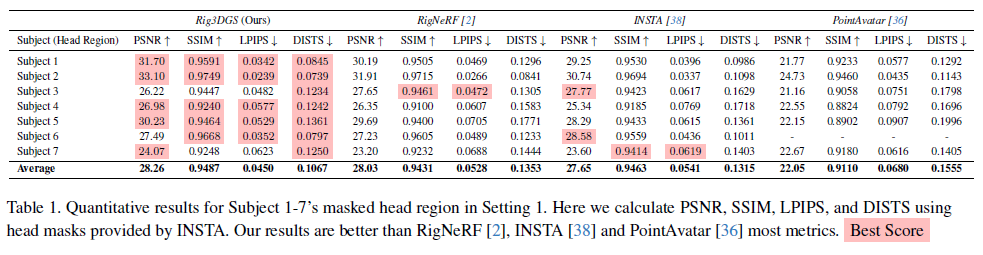 |
|
 |
 |
  |
|
반응형