PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization

내 맘대로 Introduction
제목에서 그대로 알 수 있듯이 PIFU의 HD 버전 논문이다. PiFU에서 pixel aligned feature를 이용하는 것이나, pixel aligned feature + depth z 를 입력으로 하는 occupancy network를 쓰는 것이나 동일하지만 더 성능을 끌어올리기 위해 추가 정보를 이용했다는 차이만 존재한다. 간단히 말하면 High resolution 이미지를 사용하는 module을 추가했고, front normal, back normal을 생성해서 추가 입력으로 사용한 차이가 있다.
돌이켜 생각해보면 PiFu가 NeRF의 전신 정도 되는 워낙 임팩트가 강한 논문인데 그 논문의 후속 연구라서 스포트라이트를 받은 것 같다.
핵심 내용

위 그림 중 빨간 박스에 해당하는 low-resolution 파트는 PiFU와 완전 동일하다. front/back normal 이미지를 low resolution으로도 만들어 추가 입력으로 넣어주었다는 차이만 있을 뿐 네트워크 디테일은 완전히 같다.

참고로 front/back normal map은 pix2pix (image translation GAN) 구조와 대량의 3D human model 데이터를 이용해 학습해둔 네트워크로 만든다.
high-resolution 파트도 사실 고해상도 입력을 사용한다는 차이만 있을 뿐, PiFU와 거의 동일하다. 사실 상 이미지 피라미드 입력 버전이라고 봐도 무방한 구조다.

유일한 차이는 low-resolution에서는 pixel aligned feature와 depth, z가 입력으로 사용됐다면, high-resolution에서는 depth, z 대신 low-resolution에서 넘어온 feature를 쓴다는 차이가 있다.
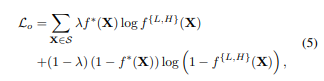
이후 extended BCE loss로 GT supervision을 이용하여 학습하면 된다.
Results

high resolution에서 depth, z 대신 low resolution feature를 넘겨받아 사용하는 것이 high resolution 추가 정보를 기존 low resolution 결과를 향상시키도록 유도하여 학습이 잘 된다고 한다.

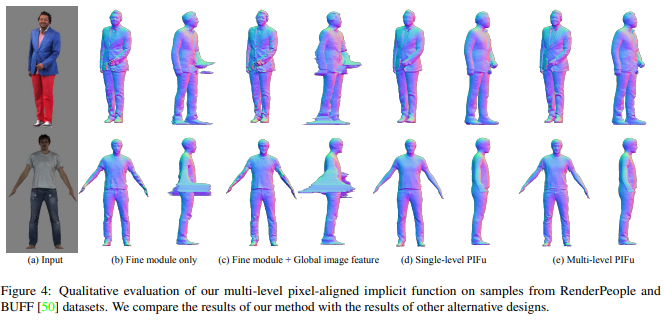

기존 PiFU 대비 좋은 성능을 정량적, 정성적으로 보이는 것이 당연하고 normal을 활용했기 때문에 디테일이 살아난 결과를 볼 수 있다고 한다.

요즘은 워낙 더 잘하는 논문도 많고 NeRF가 퀀텀 점프 성능을 보여주는 지라 별 것 아닌 것 같은데 PiFU는 꼭 기억해두면 좋을 것 같다.