H-NeRF: Neural Radiance Fields for Rendering and Temporal Reconstruction of Humans in Motion

내 맘대로 Introduction
NeRF란 고정된 대상에 대해 학습되는 알고리즘인데 이를 dynamic object, 특히 사람에 적용하려는 시도가 많이 있었다. 각종 warping 혹은 deformation을 정의해서 사람을 복원해내는 것까지 완성했는데 한가지 문제가 복원된 사람은 촬영된 이미지 범위에 한정된다는 것이다. 즉, 촬영된 이미지 상에서 취한 자세만 표현할 수 있는, 데이터 종속된 형태로 복원된다는 것이다.
이 논문은 이를 확장해서 unseen pose까지 커버할 수 있는 Human NeRF에 대한 내용이다. 핵심 아이디어는 다양한 unseen pose를 표현할 수 있는 parametric model과 implicit function을 결합하는 것이다. 대충 parametric model가 기둥을 잡아주고 implicit function이 나머지 변화를 커버하는 컨셉이다. 그래서 학습 방향도 parametric model 대비 residual을 학습하는 방향이다.
implicit function을 다루는데 parametric model은 explicit하게 되면 그 gap을 메우기가 어려우니 이 논문에서는 imGHUM을 사용한다. (애초에 이거 하려고 imGHUM을 만든 것 같기도...)
imGHUM 논문은 간단히 2023.03.13 - [Reading/Paper] - [Human] imGHUM: Implicit Generative Models of 3D Human Shape and Articulated Pos 에 정리해두었다.
논문이 top-down으로 방법론의 큰 그림부터 작은 디테일 순서대로 설명하는 식이기 때문에 이해하기 아주 좋은 논문이었다. 글쓰는 방식도 참고할 만한 좋은 논문인 것 같다.
핵심 내용


일단 전체에서 핵심 역할을 하는 것은 NeRF와 같이 위 수식이다. ray를 따라 누적한 color가 촬영으로 얻은 pixel color와 같도록 강제하는 loss다.

이를 분해해서 조금씩 내려가보면, 먼저 color, C를 만들기 위해 ray 상에서 point sampling을 할 때 사람은 형상이 잘 변하다보니 기존 물체들보다 더 sampling 효율을 높여주어야 학습이 잘 되었다고 한다.
그래서 이미지에 imGHUM을 fitting 해서 기존 NeRF 처럼 NDC(unit sphere)를 쓰는 것이 아니라 더 타이트하게 bounding box, b를 만들고 이 안에서 sampling을 한다. 또, 추가적으로 mask, M을 이용해 한 번 더 가이드를 해줌으로써 sampling을 타이트하게 해주었다.

위 그림에서 MLP가 총 2갈래로 나누어지는 것을 보면 알 수 있듯이 이 논문은 독특하게도 기존 NeRF 를 그대로 따라서 opacity랑 color를 찾는 네트워크와 SDF(정확히는 residual SDF)를 계산하는 네트워크를 병렬로 사용한다.
왜 그렇게 했는진 모르겠다. SDF를 먼저 찾고 이를 opacity로 변환해서 사용하는 방식이 VolSDF나 NeuS에서만 보아도 더 일반적인 것 같은데 독특하게 병렬적으로 써버렸다.
추측컨대 NeRF opacity로도 형상 찾는 건 가능하지만 정확하지 않다보니 잘되기로 소문난 SDF를 끼얹은 것 같다. 주 흐름을 NeRF MLP로 쓰고 SDF가 보조하는 식 같다.
추가된 SDF는 이상적이라면 opacity와 마찬가지로 형상을 정확히 반영해야 하니까 opacity와 따로따로 나오고 있지만 둘이 많이 닮아있어야 한다. 그래서 수식 (6)~(8)과 같은 독특한 식을 더 디자인해서 둘을 엮었다. (참고로 위 color loss는 수식 (4)와 별개다.)
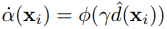
일단 SDF를 대충 scaling해서 sigmoid를 취한 값이 opacity와 같다고 정의해버리고, 이를 opacity와 섞어 사용했다. 먼저 imGHUM fitting으로 찾은 bounding box 내부에서는 SDF에서 계산한 opacity를 쓰고, 외부에서는 직접 계산한 opacity를 쓰게 했다.
또한 수식(8)과 같이 직접적으로 opacity와 SDF에서 만든 opacity가 갖도록 유도하기도 한다.
결과적으로, NeRF 에서 color loss 하나, SDF에서 color loss 하나 나오는 모양이 되고 SDF는 NeRF와 최대한 일맥상통하도록 학습이 된다. 최종적으로 결과 뽑을 때는 geometry는 SDF를 이용해서, color는 NeRF를 이용해서 뽑는다.
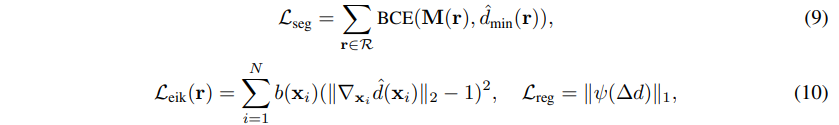
수식(9)와 수식(10)과 같은 경우는 SDF 학습이 워낙 어렵고 불안정하다보니 이를 보조하기 위해 SDF로 찾은 표면이 mask 위에 있게 하거나, eikonal loss를 이용했다.
이제 중요한 것은 실제 학습을 어떻게 dynamic scene에 대해서 학습을 시켰냐는 것인데 그것은 imGHUM에 전적으로 의존한다.
대충 말하면 특정 time step, 특정 자세에서 ray를 만들어 sampling한 뒤, imGHUM을 이용해 unpose를 한다. 즉, canonical space로 보내서 학습한다. NeRF와 SDF MLP는 canonical space 에 대해서만 학습하고 나머지는 imGHUM을 이용한 deformation으로 커버한다.
여기서 특정 time step에서 ray를 만들었을 때, 허공에서 뽑힌 point는 어떻게 unposing하느냐고 궁금할 수 있는데 imGHUM은 implicit function이기 때문에 정확히 imGHUM surface 위가 아니더라도 표면 근방이라면 unposing 할 수 있다! (이게 핵심인 듯)
추가로 학습 효과를 끌어올리기 위해 SDF MLP는 imGHUM이 내뱉어주는 SDF 값 대비 residual을 계산하는 식으로 하고, imGHUM의 pose parameter를 condition으로 같이 넣어주었다고 한다. (학습을 잘 시키려고 residual SDF를 계산하도록 했다지만 사실 residual 로 정의하지 않았으면, unseen pose를 커버하는 성능이 떨어졌을 것 같다.)
이렇게 학습하고 나면 imGHUM (implicit function) + 2차 변형 implicit function이 학습되어 다양한 pose를 표현할 수 있는 NeRF 결과물이 완성된다.
Results

결과적으로 NeRF와 IDR, 즉 NeRF MLP만 썼을 때와 SDF MLP만 썼을 때 대비 성능이 더 좋다고 한다. imGHUM의 힘인 것 같다.

시간 차이는 얼마 안나지만 이전에 나온 논문들 대비 성능도 더 높다고 하며,

애초에 목표한대로, unseen pose를 커버하는 능력도 잘 갖추어졌다고 한다.