ICON: Implicit Clothed humans Obtained from Normals
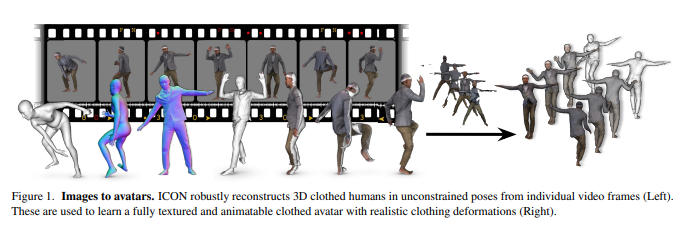
내 맘대로 Introduction
그림만 보면 영상으로부터 animatable avatar를 만들어내는 논문 같지만 실상은 frame by frame으로 3D human reconstruction하는 논문이다. 한마디로 PiFU나 PiFUHD 같은 결과를 얻고자 하는 논문이다.
sequence를 쓰는 부분이나 animatable avatar를 만드는 부분은 SCANimate를 변형해서 뒤에 갖다 붙였기 때문이다. 변형 SCANimate까지를 contribution으로 가져가기 때문에 약간의 논문이 헷갈린다.
SCANimate 논문은 이전 글 2023.03.30 - [Reading/Paper] - [Human] SCANimate: Weakly Supervised Learning of Skinned Clothed Avatar Networks 에 정리해두었다.
아무튼 그냥 이미지 to 3D reconstruction 논문이다.
핵심 내용
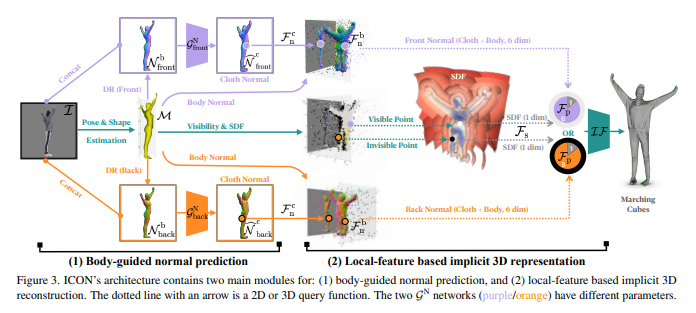
이 논문은 front와 back normal 이미지를 추정하는 STEP 1과 이를 기반으로 최종 형상을 복원해내는 STEP 2로 나뉘어져 있다. 전자는 SMPL fitting 후 front/back body normal을 미리 생성해두고 이미지와 body normal을 입력으로 clothed normal을 생성하도록 학습한다. 후자는 fittied SMPL body, front/back clothed normal을 입력으로 최종 SDF 함수, IF가 GT SDF를 맞추도록 학습한다.
많은 양의 GT normal과 GT SDF가 있어야 하는 논문으로 3D mesh 데이터가 어쨌든 꽤 많아야 학습시킬 수 있다. 논문에서 다른 기법 대비 3D 데이터 요구량이 적다고 주장하긴 하는데 과연... 의미가 있는지는 모르겠다.
STEP 1 : Body-guided normal prediction
일단 학습 이미지마다 PyMAF를 이용하여 SMPL을 정확히 fitting해둔다. 그리고 pytorch3d를 이용하여 SMPL의 front normal과 back normal을 differentiable rendering해둔다. 그리곤 normal과 이미지를 concat한 뒤 front network와 back network 각각의 입력으로 넣는다.

각 네트워크는 body normal을 이미지를 참고하여 clothed normal로 바꾸도록 학습되며 GT normal이 제공된다. 너무 간단한 구조라서 조금 놀랍다...

사용된 loss도 간단하다. 당연하게도 pixel by pixel로 GT normal과 L1 loss를 사용했고 실험적으로 perceptual loss가 도움이 됐기에 이를 추가했다고 한다.
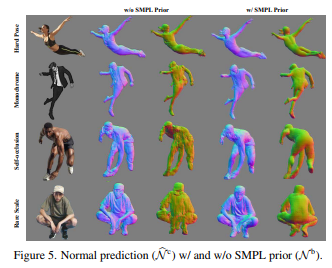
사실 특별한 것 하나 없는 것 같은데 SMPL body normal을 활용하는 것이 네트워크 성능을 크게 올린다는 것을 발견했다는 것 정도 있는 것 같다.
STEP 2 : Local feature based implicit 3D representation

적게 캡처한 것이 아니라 내용이 적다. SDF 네트워크 IF를 학습시킨다. 입력으로 들어가는 것은 특정 3D 위치 x가 있을 때 이 x가 fitted SMPL 대비 갖는 SDF, x에 가장 가까운 SMPL body point의 normal, 추정된 x에서의 clothed normal이다.
그냥 그 concat된 정보를 입력으로 SDF를 예측하고 GT SDF와 L2 loss로 학습한다.
추가 내용
SMPL fitting refinement
초기에 fitting을 수행해두고 가만히 둘 수도 있지만 ICON이 충분히 잘 학습되고 나면 normal이 잘 나오기 때문에 이 normal을 이용해서 fitting 결과를 보정할 수 있다고 한다.
fitting이 더 정확해지면 normal이 더 정확히 나오고, normal이 정확히 나오면 fitting을 더 많이 보정할 수 있으니 선순환을 이루며 점점 더 결과를 좋게 만들 수 있다고 한다.
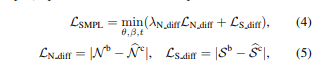
ICON에서 나온 normal와 그 mask를 이용해 L1 loss로 SMPL pose/shape parameter를 업데이트 해주는 방식이다.
SCANimate modification

SCANimate를 변형해서 사용한 것은 거창하게 말하지만 그냥 3D scan 만큼 3D reconstruction 결과가 좋진 않으니 visibiity check를 통해서 이미지에 보이는 부분에 해당하는 3D point만 썼다는 차이 뿐이다.
이미지에 드러난 부분을 네트워크가 더 잘 복원했을 것이란 전제를 이용하여 정말 약간의 변형을 한 것일 뿐이다.
Results
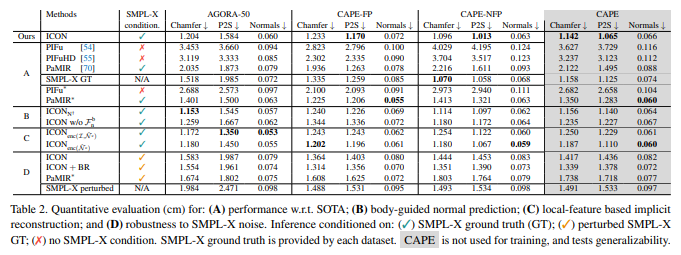
간단한데 기타 방식들 대비 정확도가 많이 올랐다.
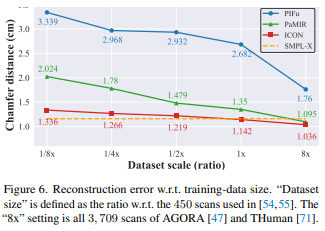
게다가 적은 양의 데이터로 빠르게 수렴하는 양상까지 보였다고 한다.

일반화도 충분히 잘되며 SCANimate를 뒤에 붙여도 잘 돌아갈 정도로 완성도가 높다고 한다.