imGHUM: Implicit Generative Models of 3D Human Shape and Articulated Pose

내 맘대로 Introduction
2023.03.13 - [Reading/Paper] - [Human] GHUM & GHUML: Generative 3D Human Shape and Articulated Pose Models 이전 글에서 소개한 GHUM이라는 모델은 SMPL 상위 호환 버전의 모델이다. 하지만 이 GHUM은 parameterization 방식이 PCA가 아닌 VAE+deep learning 기반이라는 차이가 있는 것이지 원리 자체는 SMPL과 동일한 형태의 mesh model이다. 정해진 개수의 vertex와 정해진 순서의 face를 갖고 있는 discrete model이라고 볼 수 있겠다.
이 논문은 최근 NeRF를 기점으로 관심이 높아지는 implicit representation을 human model로 가져온 논문이다. 모델이 정해진 vertex와 face로 표현되는 것이 아니라 하나의 implicit function, f(x)로 표현될 순 없을까 라는 질문으로 시작했다. 그러면 더 이상 discrete model 아닌 continuous model을 얻을 수 있게 되기 때문이다.
내용 자체는 새로운 모델을 설계하는 것이 아니라, 이미 새롭게 설계한 GHUM이라는 모델을 어떻게 하나의 implicit function화 하는지에 대해 다룬다.
핵심 내용

함수 자체는 특정 위치, p와 GHUM의 파라미터들이 들어오면 해당 위치의 SDF와 semantic label을 내뱉은 function, S와 C 2개다. 이미 GHUM 모델을 가지고 무한한 input-output을 만들 수 있는 상황에서 그렇게 난이도가 높아보이진 않는다.

학습은 IDR이나 NeuS 등 NeRF 류에서 쓰던 loss fucntion을 그대로 활용한다. 당연히 SDF GT가 있기 때문에 수식(2)의 첫항처럼 직접 SDF supervision을 제공하는 것이 있고, 수식(2)의 뒷항 처럼 normal을 이용한 supervision이 있다. 수식(2)가 가장 핵심적이다.
그 이외엔 수식(3)과 같이 SDF gradient를 1로 억제하는 eikonal loss가 사용되며, 수식(4)와 같이 너무 surface에서만 뽑으면 학습이 안되니 surface에서 떨어진 곳에서는 SDF를 0으로 보내는 loss가 사용되었다.

입력 point, p를 만들 때는 최신 내용을 다 끌어와서 normalization + positional encoding을 했다는 점을 알고 있으면 좋다.
실험적으로 이렇게 해보니 face와 hand의 표현력이 떨어지는 결과를 관찰해서 위와 같은 function을 face, left hand, right hand, body 총 네개의 부분에 대해 각각 만들었다고 한다.

function C, semantic label을 추정하는 네트워크는 특별한 것이 아니라 특정 위치, p와 GHUM 파라미터를 입력으로 받으면 해당 p가 GHUM 파라미터의 어느 vertex와 가장 유사한지 예측한다. 즉, semantic label을 GHUM vertex index와 같다고 보면 된다.
Results

반신반의하긴 했는데 결과가 잘 나온다고 한다.

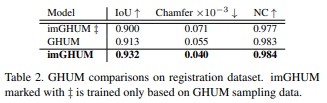
기존 GHUM과 큰 차이없는 결과를 보인다는 것으로 보아 파라미터 모델의 implicit function화가 성공적으로 이루어졌다고 볼 수 있겠다.
이 활용에 대해선 조금 생각을 해봐야겠지만 요즘 대세처럼 explicit model + implicit function으로 human modeling을 시도하는 방식을 implicit model + implicit model로 바꿀 수 있게 되는 것이니 의미는 충분한 것 같다.