반응형
내 맘대로 Introduction

PIFU랑 동일한 task를 다루지만 backbone을 ViT로 변경하고, xy, yz, zx triplane을 형성하는 식으로 feature representation을 변경한 논문. 후에 이미지에 fitting 된 SMPL face를 이용해 feature interpolation하는 식으로 body prior를 추가한 점이 또 있음.
전반적으로 backbone 탐색과 feature representation 변경이 차이점이고 PIFU 시리즈 논문이라고 봐도 될 것 같다.
메모
 |
|
 |
사실 그림만 봐도 이해가 됨... 1) image latent 생성 2) 정면은 self attention, side/top view는 cross attention으로 feature plane 생성 3) tri plane feature interpolation으로 point feature 하나하나 만든 뒤 Implicit function 학습 (like PIFU) |
  |
feature 뽑는 부분 1) ViT가 기본. 2) 정면에 해당하는 xy feature plane는 self attention으로 생성 3) side/top에 해당하는 yz, zs feature planes은 K, V는 정면에서 가져오고 Q만 별도로 YZ, ZS coordinate 값을 가져와서 cross attention으로 생성 4) 특별히 정면은 이미지랑 concat한 뒤 hourglass +super resolution으로 후처리한 feature를 사용 (더 힘준다는 의미) |
  |
query point 생성 시, 1) side/top feature는 서로 sum, 정면과는 concat하는 식으로 feature aggregation 2) 같은 feature plane 들을 갖고, 이번엔 SMPL nearest face 단위로 feature aggregation. 이 둘은 concat 됨. 3) 추가적으로 SMPL로 만든 SDF, NORMAL도 추가 . 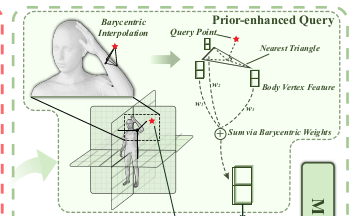 |
 |
 |
 |
 |
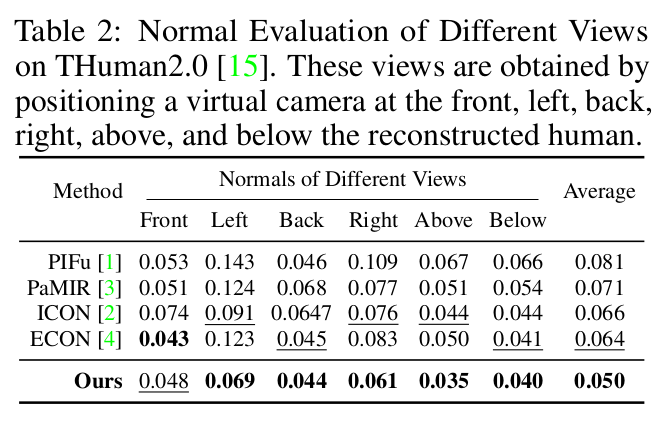 |
 |
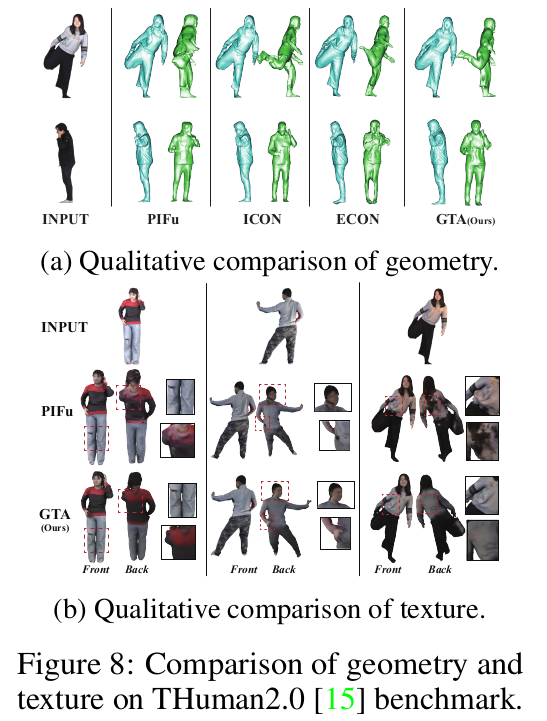 |
 나름 그래도 yz, zs가 경향이 의도한대로 흘러간다는게 신기. |
반응형
'Paper > Human' 카테고리의 다른 글
| 3D Face Reconstruction with the Geometric Guidance of Facial Part Segmentation (3DDFA v3) (0) | 2024.05.17 |
|---|---|
| Towards Metrical Reconstruction of Human Faces (a.k.a MICA) (0) | 2024.05.10 |
| POCO: 3D Pose and Shape Estimation with Confidence (0) | 2024.05.07 |
| Learning an Animatable Detailed 3D Face Model from In-The-Wild Images (0) | 2024.05.07 |
| Instant Volumetric Head Avatars (a.k.a INSTA) (0) | 2024.05.03 |