반응형
내 맘대로 Introduction

이미지 N장으로부터 표정 변화가 가능한 head avatar를 얻는 방법. 표정 변화를 모델링하기 위해서 FLAME 모델을 사용했다.
핵심 아이디어는 이미지 feature와 FLAME feature를 분리해서 inference할 때 FLAME feature만 바꿔가면서 표정 변화를 할 수 있도록 했다는 점이다. 3D consistency를 유지하기 위해서 NeRF 컨셉을 넣기도 했는데 이건 거의 유행처럼 번진 수준 같다.
동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
메모
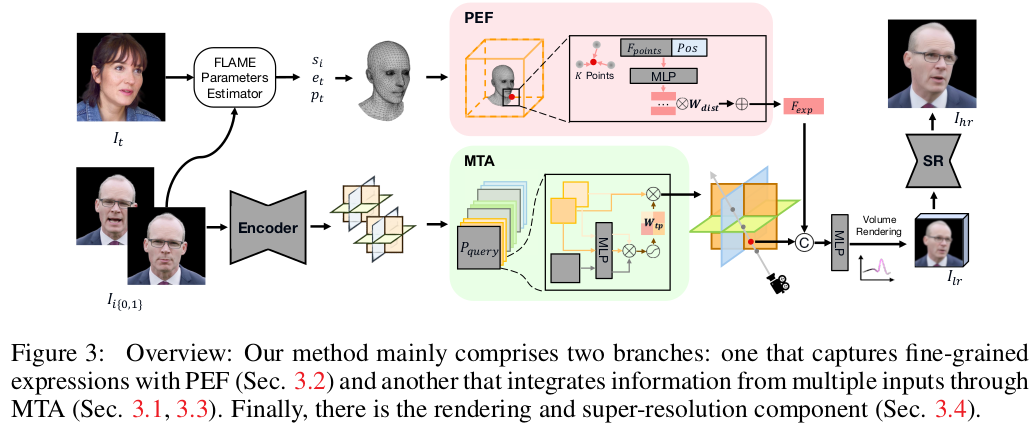  |
| 입력 이미지 N장은 FLAME 모델과 상관없이 별개로 multi plane representation으로 encoding 됨. 이 때 M개의 multi plane 들이 나올 수 있도록 자유도를 열어줬다. M개 마다 learanble Query가 주어져있어서 M번째는 고유한 feature space를 갖도록 설계되어있다. attention mechanism도 들어있음 FLAME feature는 vertex 마다 learnable feature가 부여되어 있다. 이는 나중에 렌더링할 때 ray sampling에 맞추어서 point feature로 사용된다. point feature + image feature로 이미지 렌더링 -> super resolution |
 |
| image encoder 자체는 N장의 이미지를 UNet + StyleGAN 구조로 encoding하는 역할을 한다. 특별한건 입력 이미지의 head pose를 알고 있다고 가정하고 head pose를 이용해 이미지를 affine transformation해서 사용했다. head pose에 가능한 독립적으로 이미지 feature를 뽑기 위함인듯. 그래서 이름이 canonical 붙은 것 같음. |
  |
| point feature는 FLAME vertex마다 learnable feature를 부여했다. 이미지 렌더링 ray sampling 시 어떤 위치가 주어지면 nearest point feature를 가져다가 쓴다. 참고로 ray sampling 시 얼굴 주변에서만 하면 성능이 구려서 허공도 그냥 샘플링했다고 한다. head pose를 최대한 여기서도 고려하지 않도록 하기 위해 camera 좌표계로 사용. |
 |
| 성능 때문에 허공에서 ray sampling을 했지만 허공 point에서 찾은 nearest flame point는 큰 의미가 없다. 따라서 relative positional encoding으로 넣어 학습 과정에서 거리 비례로 의미를 파악할 수 있도록 유도해주고 weight로 가중치까지 넣어서 이를 학습 시켰다. |
 |
| 이미지 feature로 나오는 multi plane들은 총 N 그룹 존재함. 각각 multiplane마다 learable query를 갖고 있어서 마치 테마를 고유하게 갖고 있도록 했음. 이미지에 따라 key와 value만 바뀌고 query는 고정되어 있는 모양. (이거 아이디어 좋은 듯.) |
 |
| 해상도 문제로 마지막에 supe resolution을 붙여주었고 크게 독특한 loss는 없다. 데이터의 양으로 승부한 것 같다. |
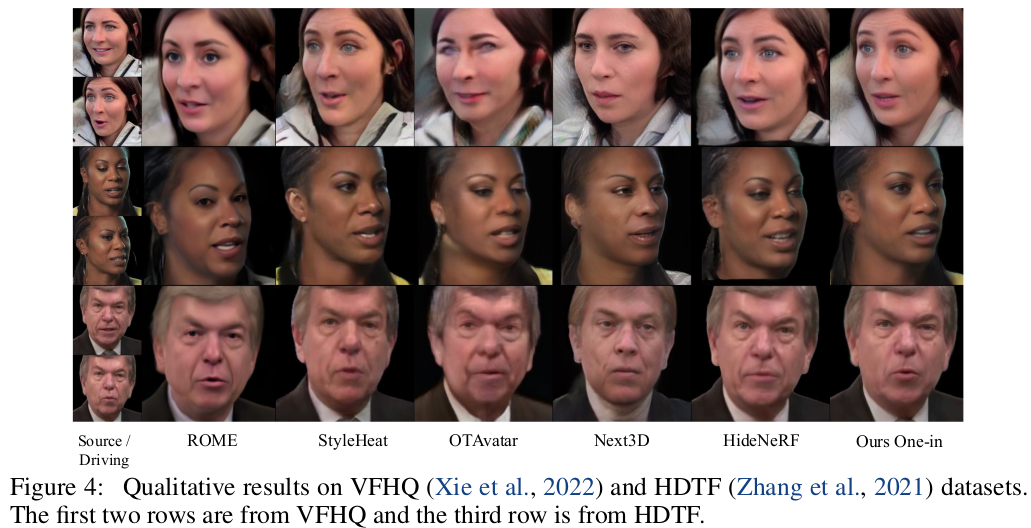 |
 |
 |
 |
반응형
'Paper > Human' 카테고리의 다른 글
| Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single Shot (0) | 2024.04.22 |
|---|---|
| Instant Multi-View Head Capture through Learnable Registration (0) | 2024.04.18 |
| StructLDM: Structured Latent Diffusion for 3D Human Generation (0) | 2024.04.17 |
| From Skin to Skeleton:Towards Biomechanically Accurate 3D Digital Humans (0) | 2024.04.16 |
| Drivable 3D Gaussian Avatars (0) | 2024.02.18 |