반응형
내 맘대로 Introduction

이 논문을 한마디로 표현하면, specific tuning이 아니라 general tuning을 하는 방법을 소개했다 생각한다. task가 motion인데 이렇게 표현하는 것이 좀 과장하는 것 같지만, 큰 그림에서 A도 motion을 갖게 하고, B도 motion을 갖게 하려면 기존에는 A,B 각각 별도로 tuning을 했어야 하는데 A, B에 둘 다 적용 가능한 tuner를 만드는 방법을 보여줬으니 general tuning 방법을 소개했다고 보인다. 간단히 말해 조금 크고 무거운 LoRA를 만들어서 여러 대상을 tuning하는 느낌이다.

개인적으로 task가 motion인데, motion을 자유롭게 컨트롤할 수 없다는 점은 아쉬웠다. 똑같은 생각을 한 사람이 있기 때문에 Animate Anyone 논문이 나왔지 않나 싶다.
메모하며 읽기
 |
이 논문 살짝 배보다 배꼽이 더 크다. recap 파트 분량이 엄청 많다. stable diffusion을 기본 pretrained model로 가져가기 때문에 다시 설명함. |
  |
fine tuning의 정석 dreambooth와 LoRA를 다시 recap함. 특히 motion module은 거대 LoRA 같은 느낌이어서 강조하는 것 같다. |
 |
|
  |
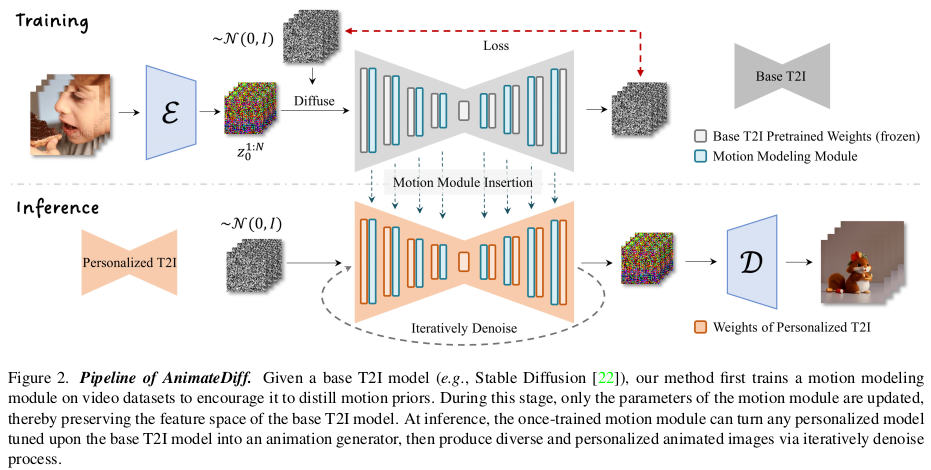
tuning 과정에서 원래 SD 모델의 성능이 저하되는 일이 절대로 없어야 하기 때문에 dreambooth에서는 regularization을 걸었지만, 여기선 통째로 freeze해버린다. LoRA에서 컨셉을 가져온 것 같음. SD의 모든 layer에 끼워넣는 용도의 motion module만 따로 학습한다. LoRA 처럼 원래 SD는 그대로다. |
 |
SD는 처음부터 끝까지 freeze된 상태이며, motion module만 업데이트 된다. motion module은 대상마다 같은 task 별 tuning을 반복하는 문제를 해결하기 위해 제안된 것인 만큼 여러 대상이 같은 task에 대해선 공유할 수 있다. 즉, motion 만드는 task로 학습을 시켜두면 대상(prompt)이 바뀌어도 그대로 동작한다. |
  |
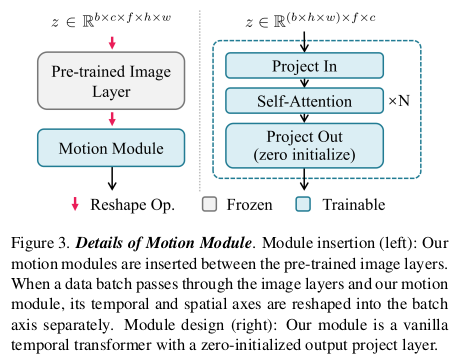 이미 학습 완료된 SD에 temporal 차원이 추가돼서 dimension이 하나 더 큰 motion module을 끼워넣는 일이 구현 상 불편하다. 이를 해결하기 위해서 SD에 넣을 때는 temporal 차원(frame 차원)을 batch dimension에 포함되도록 reshape했다. (b*f, c, h, w) SD는 그럼 Temporal 차원에 대한 구분력이 모든 frame을 각각 독립적으로 다룬다. 뒤 이어지는 motion module에서 temporal 차원을 살리기 위해서 이번엔 spatial 차원을 batch에 포함시키고 temporal 차원을 활성화 한다. (b*h*w, c, f) motion module은 그럼 temporal 차원 구분력을 제공하게 된다. 결론적으로 temporal 차원을 고려하도록 학습 가능. -------------- motion module의 구조는 temporal transformer, 즉 b*h*w, c, f로 reshape해서 처리하는 방법의 기본 구조를 사용했다고 한다. |
 |
학습은 모든 time에 대해서 GT를 갖고 있는 video dataset으로 한다. 대규모 video dataset에 대해서 motion module을 학습시키는 것. 그러면 생성 모델이 알아서 대충 motion을 입혀서 뱉어줌. loss는 diffusion loss 그대로 인데 time에 따라서 다 적용한 차이 뿐. |
 |
 |
  |
 |
반응형