반응형
내 맘대로 Introduction

또 하나의 3D GS 후속 연구 중 한걸음 나아간 논문이 나왔다. 제목에서 볼 수 있다시피, 기존 3D GS 대비 성능 드랍 없이 속도를 훨씬 빠르게 한 논문이다. 핵심 아이디어는 1) gaussian pruning (filtering) logic을 추가해서 절대적으로 3D GS 수를 줄인 것 (내가 하고 싶었던 것이다.) 2) gaussian parameter를 quantize해서 용량 자체를 물리적으로 줄인 것. 이 두 개를 조합하니 성능은 오르고 속도는 빨라지는 결과를 얻을 수 있었다.
2)에 해당하는 내용은 둘째 치고 1)에서 pruning한 방법이 주요 포인트다.
메모하며 읽기
 |
|
 |
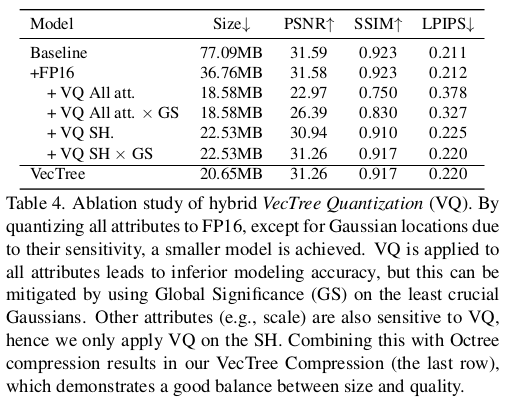
크게 3가지 과정으로 구성된다. 1) gaussian pruning - multiview scoring을 이용해 제거하기 2) SH distillation - high degree SH랑 비슷한 성능을 내는 low degree SH coefficient 찾기 - 학습 완료한 후에 후처리로 하는 것 3) SH 외 나머지는 quantization 기법 적용하기 - 중요한 GS를 quantization하면 성능이 떨어지니, 하위 60%만 quantization! |
 |
  |
 |
 |
| 먼저 분석을 했다. 학습 완료된 기존 3D GS 결과를 보면 왼쪽 그래프와 같이 opacity가 0 아니면 1에 가깝도록 양분된다. (유리나 거울 같은 반투명 물체가 없다면 당연한 것 같다.) 이 때 0에 가까운 애들은 noise일 수도 있지만, 디테일을 묘사하기 위해 생성된 애들이라고 볼 수 있다. 따라서 opacity만 갖고 0 근처 Gaussian을 단순히 제거해버리는 식으로 pruning을 하면 아래 그림과 같이 디테일이 사라지는 성능 저하 이슈가 있다고 분석했다. 결론적으로 opacity를 이용한 단순 pruning이 아니라 특별한 score를 이용해 pruning하는 방식이 고안되어야 된다. |
|
  |
GS마다 렌더링에 얼마나 기여하는지 그 score를 먼저 정의를 해야하는데 총 3가지를 보았다. 1) 렌더링에 참여하는 횟수 2) GS 자체의 opacity 3) GS 자체의 크기 다 클수록 유의미한 GS로 보기에 적합한 metric인 것 같다. 1) 2) 3)을 곱하는 형식으로 global score를 정의했다. ** opacity 0인 애들이 pruning되기 쉬운 것은 여전히 맞다. 하지만 렌더링에 참여하는 횟수가 많다면 그리고 크기가 크다면 살아남을 가능성을 높여주므로 이전보다는 낫다. 여기서 3) GS 자체의 크기를 정의할 때, 단순히 scale 값을 사용할 수도 있겠지만 절대적인 값으로 할 경우, 복원 대상이 클 때와 작을 때 범용적으로 적용될 수 없으므로 normalized volume을 사용했다. 현 상태의 GS 중 상위 10% 정도 위치에 있는 크기를 기준으로 normalization 한뒤 ,0~1로 clipping해서 사용했다. 이러면 상대적으로 큰 애들이 score가 높으므로 복원 대상이 물리적으로 얼마나 크냐 작냐는 중요하지 않게 된다. |
  |
score를 갖고 이제 pruning을 직접 한다는 소리인데 Gaussian adaptation이라는 용어가 따로 있어서 굉장히 복잡한 것인줄 알았지만 코드를 보아 하니,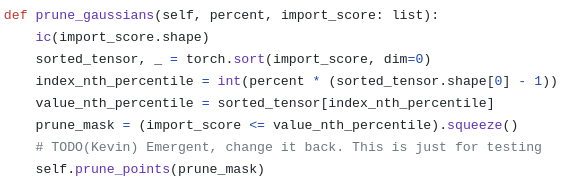 대충 몇 퍼센트 잘라낼건지 정해서 그냥 잘라낸다. |
 |
다음 핵심인 SH coefficient를 경량화하는 부분이다. 기존 3D GS의 경우 SH coefficient를 48개나 사용하게 되는데 이게 전체 파라미터의 81.3%나 차지하는 대용량이다. 따라서 이것만 줄여도 용량을 어마어마하게 줄일 수 있다. 3D GS 결과에서 SH coefficient를 잘라내서 사용해도 되지만 성능 저하가 분명히 있을 것이므로 low SH coefficient를 새로 찾아내는 방식을 사용했다. 일종의 distillation인 것이다. 실제 training view에 대해서, 그리고 가상 view에 대해서 기존 SH coefficient로 색상을 만든 것과 low SH coefficient로 색상을 만든 것이 같도록 계속 학습한다. 결과적으로 low SH coefficient가 조정되면서 high SH coefficient가 갖고 있는 색상 표현력을 최대한 흉내내도록 수렴한다. 단순히 잘라내서 쓰는 것보다 이게 성능이 좋았나 보다. |
 |
앞서 가상 view도 사용했다고 했는데, 이는 SH coefficient 자체가 view-dependent color를 표현해주기 때문에 training view로는 모든 view를 보여주면서 low SH coefficient로 distillation하는 것이 어렵기 때문이었다. GS에 주어진 SH cofficient를 바꿔치기하는 것이므로 SH 외 GS파라미터를 고정하고 무작위로 렌더링만 반복하면서 color를 찾는 것이 더욱 효과적이다. 따라서 기존 training view에 translation만 noise를 주어 가상 view를 더 만들어 학습했다. |
  |
여긴 사실 잘 이해 못했다. 1) global score를 가져와서 3D GS를 sorting한다. 상위 40%는 그대로 두고 하위 60%만 quantization 대상으로 선정한다. 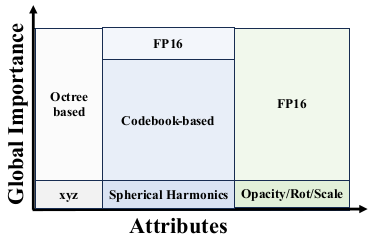 상위 40%는 아무것도 건드리지 않고 그대로 저장하는 방식이고 나머지는 각각 적합한 방식으로 quantization 된다. 1) xyz position, octree based quantization global score가 높은 GS 위치를 기준으로 octree를 만들어가는 식으로 위치를 저장함 2) SH code-book을 만들어서 SH coefficient를 더 적은 값으로 표현할 수 있게 함. 3) opacity, rotation, scale은 fp16으로만 |
 |
2) SH SH 를 low degree로 distillation하는 것에서 더 나아가 codebook을 만들어 한 번 더 간소화해준다. codebook이란 대충 이해해보자면, 주어진 N개의 값들을 K개로 clustring한 뒤 그 center 값이라고 볼 수 있겠다. N개의 값을 들고 있는게 아니라 K개 값과 N개의 index만 들고 있도록 하는 것이다. 찾는 방식은 clustering과 비슷하다. batch 단위로 샘플링하면서 moving average를 찾는 식이다. 정확한건 안나와 있어서 모르겠다. |
 |
1) xyz position 이 부분은 구현적인 내용이 우선이고 기술적인 건 모르기 때문에 사실 넘어갔다. 대략 score가 높은 point를 기준으로 octree를 형성하면서 point들을 순차적으로 정리한다는 것 정도 감잡았다. |
 |
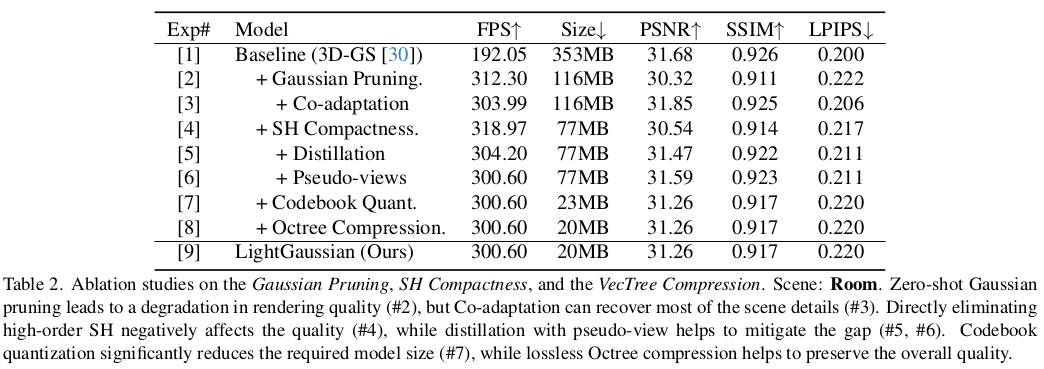 |
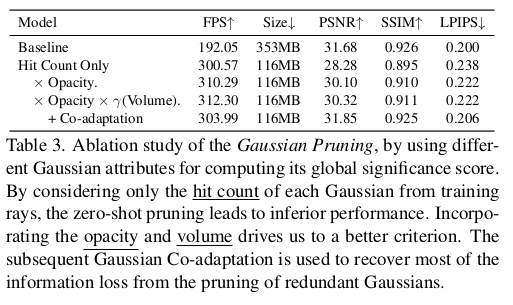 |
 |
 |
|
 |
 |
 |
반응형