큰 그림 그리기
TensorRT는 engine이라고 부르는 optimized representation으로 모델을 변환하는 것과 engine을 deploy하여 실제 디바이스에서 동작시키는 두 가지 과정으로 구성되어 있으며, 이 두 가지 과정을 끝마쳤을 때 경량화했다고 할 수 있겠다.

전체 흐름도는 위와 같다.
- 모델 선정
- batch size 고정
- precision 설정 (quantization)
- 모델 변환
- 모델 배포
3) precision 설정은 layer 별로 혹은 전체에서 몇 bit 쓸 건지 결정하는 과정이다. 일괄적으로 낮추는 것이 기본 세팅이지만 성능 하락 문제가 동반되므로 layer 마다 다른 설정을 두는 것이 좋다. 그럴 경우, quantization 분야로 넘어가는 영역이 된다.
세부 그림 그리기
앞서 언급한 두가지 과정은 각각 conversion, deployment라고 불린다.
conversion이라 함은 engine화 하는 것인데 대상이 python인지 c++인지, pytorch인지 tensorflow인지, onnx인지 등 경량화 전 모델이 어떤 타입이냐에 따라 engine화 하는 과정이 당연히 다를 것이다.
범용적으로 모델을 engine화하는 기능 전체가 convresion 파트다.
동시에, 만들어진 engine을 실제로 사용을 해야할 때도 tensorflow인지 pytorch인지, triton서버에서 할지 로컬에서 할지, gpu 모델이 뭔지, python인지 c++인지 등에 따라 engine이 동작하는 방식이 다를 것이다.
만들어진 engine을 실제 사용 환경에 맞춰서 run 할 수 있도록 하는 부분이 deployment 파트다.
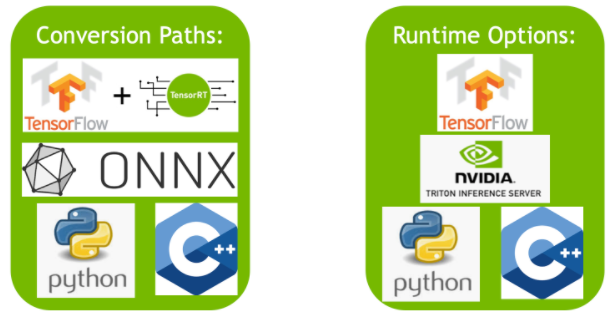
conversion
"범용적"으로 모델을 engine화할 수 있다고 해서 모든 경우의 수가 다 가능한 것은 당연히 아니다. 대표적으로 3가지 지원된다.
1) onnx : onnx란 open neural network exchange의 축약어로, 각기 다른 딥러닝 프레임워크 간 모델 변환이 용이하도록 돕기 위해 만들어진 공유 플랫폼이다. 이미 공유 플랫폼이 존재하는 이상 onnx에서 tensorrt로 변환하는 과정만 구현하면 일이 쉽기 때문에 onnx-to-tensorrt가 지원되고 권장된다.
2) TF-TRT (tensorflow integration) : tensorflow에 한정해서는 직접 tensorrt로 변환할 수 있다. tensorflow의 일부 operator는 지원되지 않는데, 그 리스트는 다음 링크에 기록되어 있다. 지원 operator list를 확인해보면 알겠지만 결국 이 방식도 onnx과 엮여있다.
3) TensorRT API로 직접 구현된 모델: TensorRT에서 제공하는 layer class를 이용하여 직접 모델을 디자인하는 방법이다. 자체 지원 layer로 모델을 구현했기 때문에 변환 개념이 아니라 설계에 가깝다. 이 방식은 솔직히 초보자 레벨에서 무리가 있으며 권장되지도 않는다. 모델 구현하고 나서 학습하는게 아니라 사전 학습된 모델 weight를 이식해야 하기 때문에 처음부터 변환되는 모델 잡고 시작하는게 낫다.
결론적으로 모델을 tensorrt engine으로 변환하려면 사실 상 onnx로 변환해야 한다.
실제로 "The result of ONNX conversion is a singular TensorRT engine that allows less overhead than using TF-TRT." 라고 적혀있어, onnx에서 trt engine으로 가는 것이 성능적으로 더 좋기까지 하다.
Deployment
역시 실제 사용 환경에 "맞춰서" 동작할 수 있도록 한다고 해서 모든 환경에 맞출 수 있는 것은 아니다. 총 3가지 방식으로 deployment 할 수 있다.
1) Tensorflow : 이름도 비슷하고 google과 친해서인지 tensorflow로 deploy하는 것은 그냥 지원된다. TF-TRT가 따로 있으니 당연한 것 같기도 한데, trt engine을 tensorflow로 동작시키는 것이 가능하다.
2) standalone TensorRT runtime API : TensoRT 자체에서 runtime 동작을 위해 제공하는 api들이 있다. python/c++이 존재하고 api를 사용해서 engine을 동작시키는 코드를 구현할 수 있다.
3) NVIDIA Triton Inference Server : nvidia에서 만든 것 답게 engine을 서버를 통해 돌릴 수 있는 기능도 제공한다. 애초에 서버로 쓰는 GPU도 nvidia 것이니까 기기부터 서버 기능 지원부터 다 nvidia 소유 이므로 engine을 기존 서버 기능 지원에 붙이는 것이 당연해보이기도 한다.
개인적으로, 경량화한 trt engine을 사용하기 위해선 Triton이 필요하다는 구조로 만들어두니 자사 서버를 더 팔 수 있는 그림이 나오고 회사 입장에서 돈을 벌 수 밖에 없는 구조가 된 것 같다.
정리하면 TF-TRT conversion했을 시에만 tensorflow deploy 나머진 2) 방식대로 직접 inference 코드를 구현해서 사용한다고 보면 되겠다. 서버를 사용할 경우에만 특별하게 triton을 사용한다.
TensorRT workflow
conversion/deployment로 나뉘어지고 그 안에서 각각 여러가지 범용성이 지원된다는 것을 위해서 보았다. 전체적으로 정리해서 실제로 모델을 경량화하고 싶을 때 어떤 workflow로 진행하면 되는지 보자.

일단 첫 시작은 모델이 tensorflow인지 보는 것이다. 맞으면 TF-TRT 아니면 ONNX. TF-TRT면 바로 끝.
ONNX라면 deploy가 c++로 이루어지는지 python이루어지는지 확인한 뒤, 각각 API로 구현하면 된다.
Note
ONNX-to-TRT는 all-or-nothing 방식이다. 즉 모든 layer가 다 변환이 되어야 변환이 완료된다. onnx로 변환이 안되든, trt로 변환이 안되든 한 과정에서라도, 한 layer라도 실패하면 전체 과정은 실패한다. 이 경우 실패하는 layer 혹은 모듈을 custom plug-in 형태로 따로 구현해서 변환 과정에 포함시켜줘야 한다.
(이건 어나더레벨 구현이라서 실패하면 layer를 바꾸는게 낫다.)
'Knowhow > Others' 카테고리의 다른 글
| [TensorRT 튜토리얼] 3-2. TRT engine deployment (TBU) (0) | 2024.01.22 |
|---|---|
| [TensorRT 튜토리얼] 3-1. ONNX/TRT engine conversion (0) | 2024.01.22 |
| [TensorRT 튜토리얼] 2. Docker container (0) | 2024.01.19 |
| [TensorRT 튜토리얼] 1-2. cuDNN installation (0) | 2024.01.19 |
| [TensorRT 튜토리얼] 1-1. CUDA installation (0) | 2024.01.19 |