반응형
내 맘대로 Introduction

그림만 보아도 이젠 알 수 있듯이, 저자는 다르지만 HMR 시리즈의 연속작이다. 이미지 feature에서 SMPL 파라미터를 어떻게 잘 뽑아낼 것이냐를 고민한 논문이다. (파라미터를 직접 뽑진 않지만, mesh model로 바꾸려면 이 논문도 SMPL 파라미터를 찾아야 된다.) 이미지 feature를 이미지 전역에서 쓰는 것이 아니라 vertex에 해당하는 위치에서만 sampling해서 쓰면 성능이 올라간다는 주장이다. task 자체는 성능 수치 싸움을 하는 레드오션 task를 그대로 다루고 새로운 task를 정의한 것은 아니다. 핵심 트릭을 파악하면 되는 논문.
내가 느끼기엔 PyMAF와 매우 유사한 컨셉이고 다만 joint 레벨에서 vertex 레벨로 더 차원을 높였다는 정도의 차이인 것 같다. 염려되는 것은 연산량인데, 2D heatmap을 뽑는데 차원을 줄여서 431개를 썼다고 한다만 수십배 늘어난 채널이라 computational power가 엄청나게 필요할 것 같은데 뒷단의 backbone이 transformer라서 더 클 것 같다. 성능 이전에 실사용성이 떨어지지 않을까 싶다.
메모하며 읽기
  |
| 전체적으로 두 파트이며 첫 파트가 feature 모아주는 곳, 두번째 파트가 trasnformer로 regression하는 곳이다. |
  |
HRnet으로 feature encoding 한 번 해준 뒤, heatmap을 뽑는다. SMPL vertex 6천개 쓰는 건 말이 안되니 대표 431개만 썼다고 한다. (HRnet에다가 채널 431개 heatmap이니 메모리 장난아닐 듯.) heatmap * feature로 vertex feature 만들고 flatten해서 transformer에 넣는 작업 여기서 feature는 HRnet 통과한 통 feature에 그대로 곱한다. feature를 뽑을 때부터 vertex 레벨로 분리해서 뽑진 않는다. |
  |
transformer는 target feature 외에 joint token, grid token을 받음. joint token은 trainable parameter고 grid token은 첫번째 파트에서 나온 것을 씀. (근데 grid token에 대한 구체적 언급은 없다... 그냥 HRnet feature에 decoder 작은 것 붙여서 따로 feature 만들고, positional encoding 더해서 만든 것인듯.) vertex 거리가 너무 멀 경우 굳이 attention할 필요없다고 가정하여 거리 기반으로 self-attention을 필터링한다. 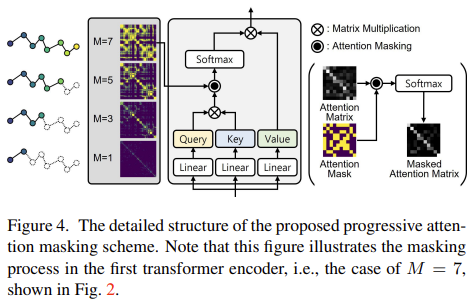 Q, K로 만든 attention map에 곱해주는 형식이고 깊어질수록 범위를 축소해서 국소적으로 집중할 수 있도록 유도한다.  실제로 효과가 있다고 함. 최종 output은 431 vertex 3D coordinates인데 upsampling해서 6890개로 만들어서 mesh 만든다. |
   |
vertex loss는 prediction - GT 간 L1 loss 다. vertex GT가 있어서 사용할 수 있음 joint loss는 joint token으로 만든 것과 vertex에다 SMPL joint regressor 곱해서 만든 것에 각각 L2 loss 걸었다. projection 해서 2D 도 마찬가지. orthogonal projection 썼을 듯. heatmap loss는 역시 GT heatmap과 bineary cross entropy이다. dice loss를 추가했는데, (처음 들어봄...) 아마 여러 joit가 한 픽셀에 겹치는 경우에 대응하기 위해 요즘 개발된 loss인가 보다. 겹치는 heatmap끼리 약간 서로 밀어내는 효과를 주는 수식으로 보임 학습은 A6000 2장 썼다고 함. 두 개 합쳐서 96GB니까 단일 모델치고 메모리를 많이 쓴 것은 맞다. |
 |
 |
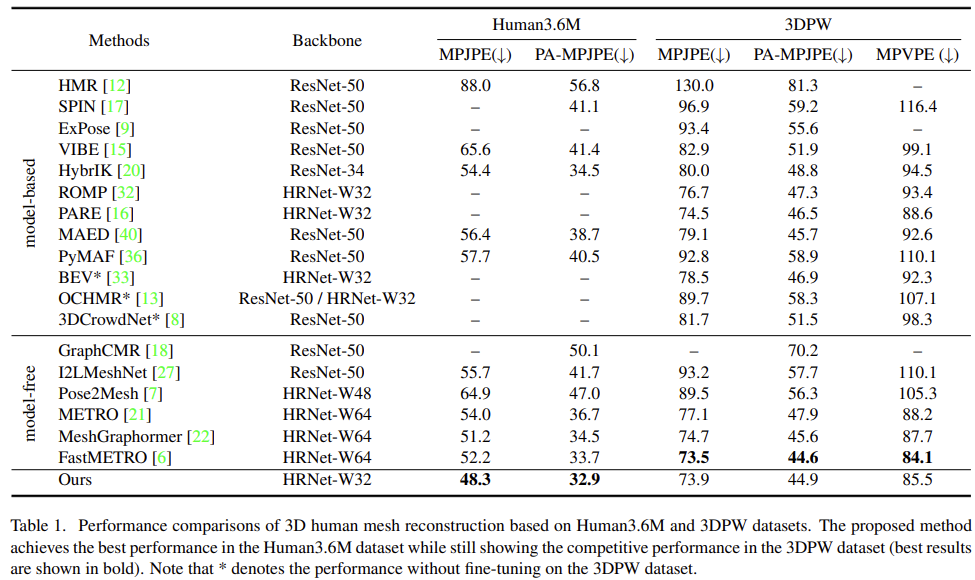 |
반응형