Neural Body: Implicit Neural Representations with Structured Latent Codes
for Novel View Synthesis of Dynamic Humans

내 맘대로 Introduction
이 논문은 NeRF를 움직이는 사람을 타겟으로 한정한 논문이다. "움직이는 사람의 자세"에 대한 condition이 추가된 NeRF라고 보면 된다. NeRF 관련 논문들이 쏟아져 나오기 시작하면서 나온 논문으로 당연히 나올 것 같다고 생각한 주제다.
이 논문은 NeRF가 소개된 이후 초창기에 나온 논문이기 때문에 독특한 방법론이 있다기 보다 움직이는 사람 자세를 어떻게 condition으로 넣어줄 것이냐만 추가한 단순한 논문이라고 볼 수 있다.
쉽게 예상할 수 있듯이 이미지에 fitting한 SMPL을 이용했고, SMPL의 6890개 vertex 마다 latent code를 부여하고 이를 입력으로 같이 주었다. 그 외엔 특별한 것이 거의 없다.
핵심 내용
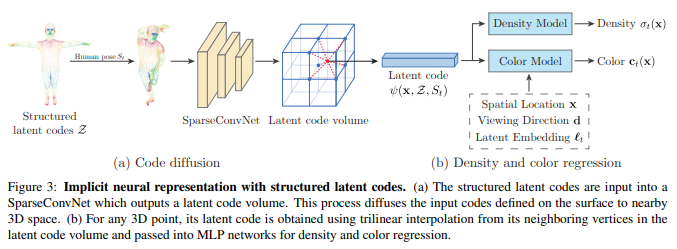
먼저 시작은 SMPL vertex마다 사이즈 16을 갖는 latent code를 부여하는 것이다. zero pose (T-pose) 상태일 때 한 번만 정의하면 된다. 논문에 어떻게 latent code를 부여하는지 디테일은 없어서 정확한 방법은 모르겠으나 크게 두가지 방법이 있을 것 같다.
- auto-encoder 구조로 설계해서 만들어 두기 (vertex 별 latent code가 완전히 독립적을 형성되도록 하는 트릭은 필요하겠지만)
- learnable latent code로 남겨두기 (왠지 이 방법일 것 같다.)

그런 다음 특정 time, t을 학습할 때 미리 fitting된 SMPL 파라미터를 이용해 앞서 만든 vertex 별 latent code를 transformation하여 time, t의 defomred volume에 채워넣는다. 그리고 NeRF 입력으로 point, x,를 넣어줄 때 해당 위치에 채워진 latent code를 concat해서 넣어주는 식이다. 이렇게 사람 자세에 대한 condition을 NeRF에 넣어줬다. (매우 단순)

당연하게도, SMPL vertex는 6890개 밖에 안되기 때문에 이를 이용해 deformed volume을 채워본들 굉장히 많은 voxel들이 텅텅 비어있을 텐데, 이를 해결하기 위해서 SparseConvNet이라는 3D convolution 기반 네트워크를 한 번 통과시켜 pyramid형 volume feature를 만들고 이를 이용했다.
이렇게 3D convolution을 통하면 비워져있는 voxel들이 convolution에 의해 어느 정도 채워지고, pyramid 구조까지 이용하니 꽤 쓸만한 새로운 latent code volume을 만들 수 있을 것 같다.

뒤는 당연하게도 그냥 NeRF 구조를 그대로 썼다. S_t 라고 표기된 것이 하나 더 추가됐는데 이것은 덤으로 time, t 에 fitting 되어있던 SMPL의 pose paramter다. latent code와 더불어 사람 자세에 대한 condition을 더 강하게 줄 수 있을 것이란 기대에 같이 사용한 듯 하다.
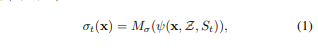
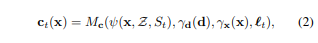


사용한 수식 뭉터기도 NeRF와 100% 동일하다. 이 때까지만 해도 새로운 수식을 생각해내기 보다 확장에만 집중했던 시기라 그런 것 같다.
Results

사람 위주로 촬영한 ZJU-MoCap 데이터셋에서 실험했을 때 효과적인 view synthesis 결과를 보여줬다고 한다.

density를 이용하여 mesh화한 결과가 PiFU 와 비빌 수준이 나왔다거나 people snapshot 데이터셋에서 이전 논문보다 높은 appearanace 표현력을 보였다는 것을 말한다. (옛날 얘기다 벌써)
