반응형
내 맘대로 Introduction

single image에서 3d human avatar 얻어내려는 시도가 워낙 많아서 이제는 이 논문이 저 논문 같고, 저 논문이 이 논문 같다. 방법론은 대개 비슷한 것 같고 누가 누가 더 많은 데이터로 완성도 있게 만들었냐를 경쟁하는 듯 하다.
이 논문 역시 SMPLX query point (feature) + image feauter --> transformer --> per-vertex 3D Gaussian parameter 이런 흐름이다. Feature extractor로 Sapiens에 DINOv2까지 갖다 붙이고 transformer로 decoding 하는 방식.
메모
 |
|
 |
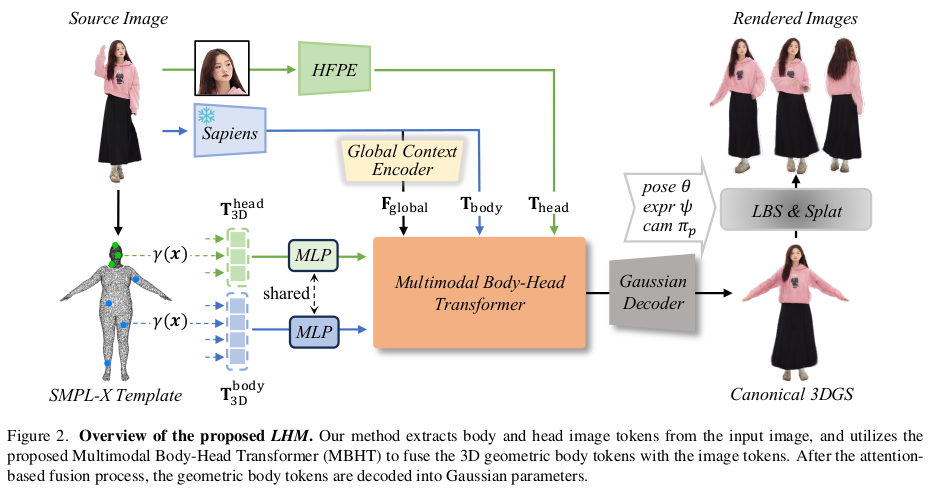
목적이 뚜렷하다. SMPLX per-vertex 3DGS 를 만들건데, LBS로 자세 바꿨을 때 다양한 view에 최대한 맞아떨어지게 만들 것. |
  |
SMPLX per-vertex 값이므로 per-vertex가 query로 주어진다. pos-emb하고 MLP까지 붙여서 queyr point feature 만들기 |
 |
이미지를 통쨰로 토큰화하면 얼굴 성능이 조금 아쉽다고 한다. 그래서 얼굴 주변 영역만 CROP해서 추가 head token을 만들어 줌 body는 sapiens로 head는 DINOv2로 |
 |
body token은 첫번째로 max pool + MLP를 통해 global context feature로 바꿔둔다. |
 |
global context feature <-> head token 이랑 한번 global context feature + head token <-> body token이랑 한번 이런 순서로 body-head를 섞어줬다고 함. --------- head랑 body를 섞었다는 의미로 multi-modal이라는 단어를 붙인 듯 하다. 일반적으로 쓰는 의미랑 좀 다른 듯. |
 |
이렇게 해보니, head만 되려 너무 강조돼서 body가 안 좋았다고 함. head vs body 비율 조절을 하기 위해서 학습할 때 head region만 MAE하듯이 mask patch를 조금 섞어줬다고 함 --------- 최종 feature를 MLP를 통해 각 3dgs param으로 변환 canonical space에서 예측한다. |
  |
Rendering [ LBS(canonical) ] vs image 이런 식으로 loss 계산 LBS는 SMPLX꺼 쓴다. |
 |
gaussian이 크기가 너무 뾰족하거나 납작하게 나와버리면 LBS에 artifact가 너무 뚜렷하게 보이니까 웬만하면 Gaussian이 동글동글하도록 scale이 1 1 1 에 가깝도록 유지. 너무 크지도 않게 억제하는 효과 |
 |
3dgs 가 per-vertex domain에서 예측되는 만큼 본래 SMPLX vertex에서 많이 벗어나지 않도록 함 as close as possible 이라고 불렀지만 그냥 익히 알려진 displacement 억제하는 것. |
 |
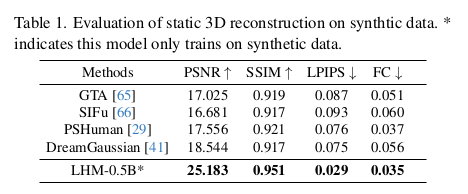
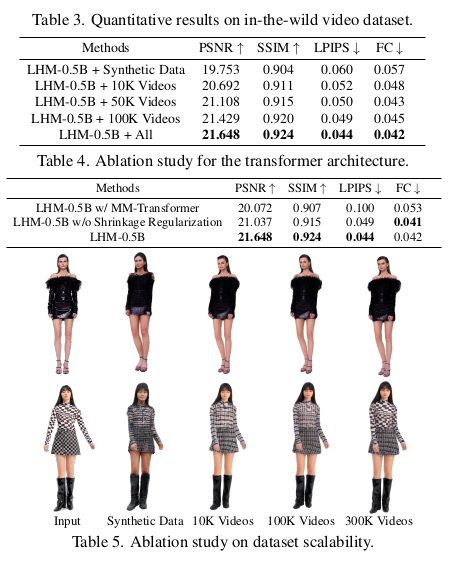
비디오를 대량으로 쓴 것이 핵심인 듯. 어떻게 SMPLX를 fitting했느냐가 더 관건인 것 같다. 이게 엄청 정확해야 성공할텐데. 나중에 데이터셋 받아봐서 확인해야 할듯. (이부분 대단하다.) 나머지는 synthetic 데이터를 사용했다. |
 |
 |
  |
 |
반응형