반응형
내 맘대로 Introduction
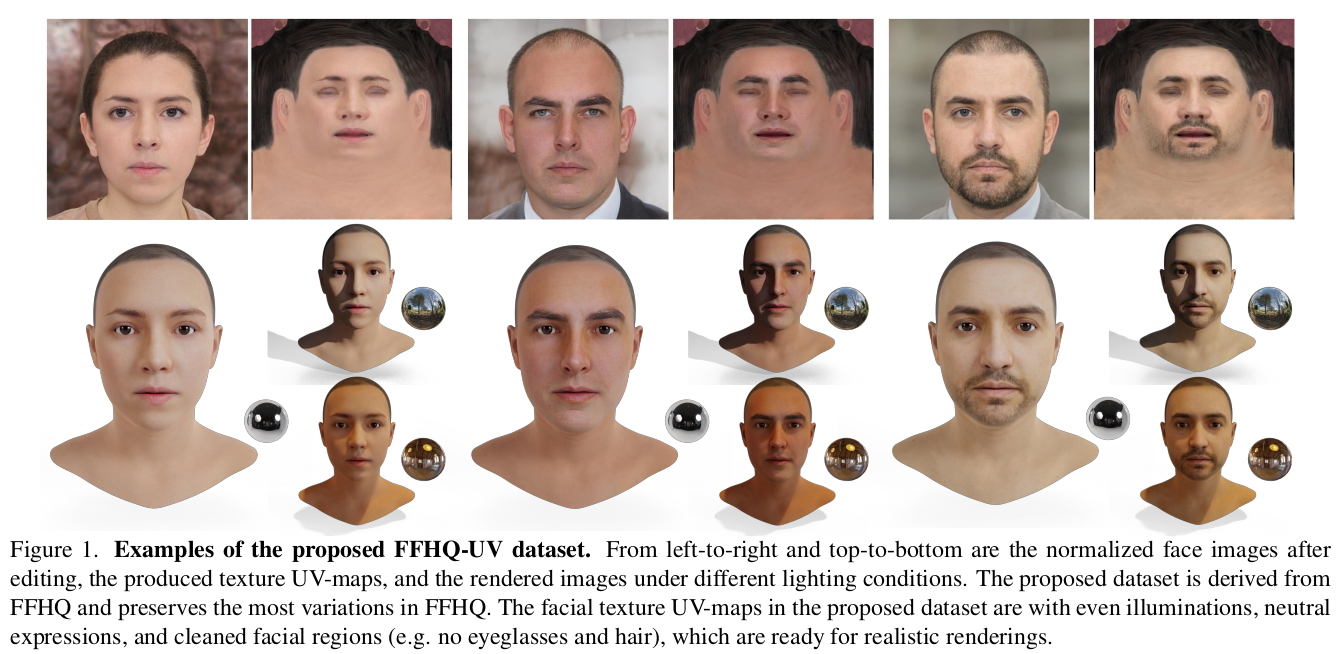
이 논문은 FFHQ 데이터세에 있는 얼굴들의 texture를 뽑아내서 데이터셋화 한 논문이다. 이미지 말고는 주어진 정보가 아무것도 없는 FFHQ 데이터셋에서 정해진 UV 도메인의 texture map을 뽑아내는 것이 목적이기 때문에 이미지 to scan, scan unwrap 등 여러 요소가 끼어들어야 했다. 결과적으로 기존에 등장했던 여러 SOTA 알고리즘을 총집합해서 끄끝낸 만들어낸 데이터셋 내용이다.
데이터셋 논문이다 보니 알고리즘 적인 내용보다 어떻게 처리했는지 디테일 위주다.
메모
 |
|
 |
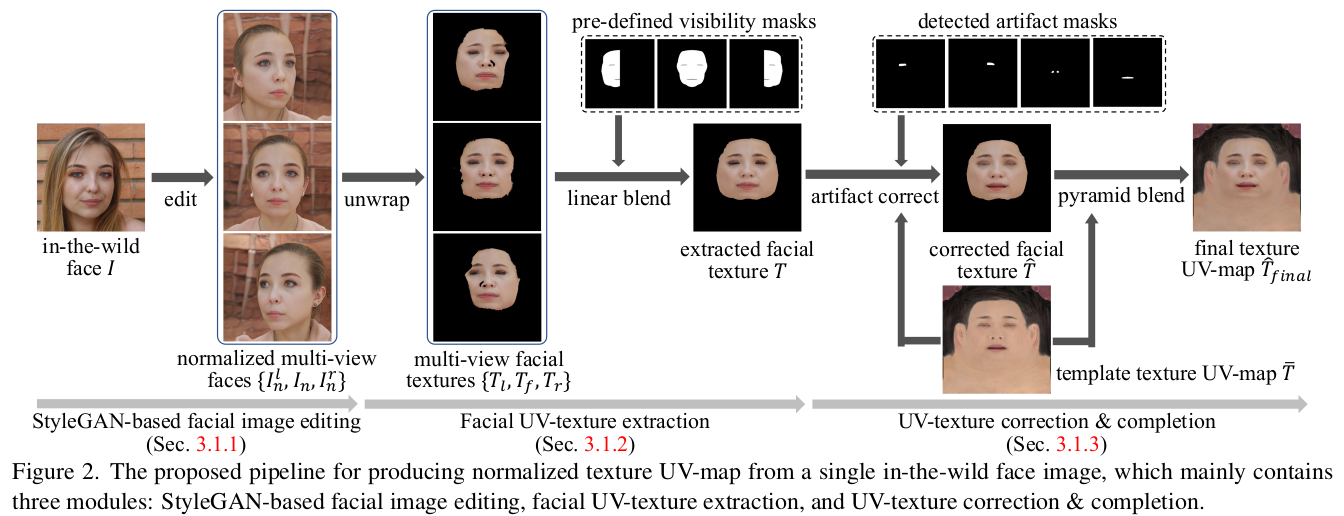
크게 3단계다. 1) 이미지를 InterFaceGAN으로 multiview + 머리 없애고 + 안경 없애고 2) Deep3D 알고리즘을 자체 학습한 것을 돌려 3D Mesh 뽑아내기 3) 3D mesh를 따라 unwrap 4) multiview unwrapped 이미지를 YUV color matching으로 블렌딩 5) 콧구멍, 입구멍, 머리카락은 불안정하니 template texture로 덮어쓰기 |
 |
1) InterFaceGAN은 head pose, eyegalss, hair 같은 property 조절이 가능한 GAN이다. 입력 이미지를 InterFaceGAN inversion을 통해서 latent로 바꾸고, 이 latent에서 eyeglass, hair, expression을 없애서 neutral latent를 만든다. 2) 추가적으로 DPR 모델을 붙여서 light 까지 normalize 3) StyleFlow 붙여서 빛을 고르게 다시 뿌림 4) Multiview condition 줘서 multivew image 생성 |
  |
사실 상 이미지 to mesh가 안되면 만들 수 없어서 mesh를 얻어내는게 제일 핵심인데 Deep3D 모델을 썼다. 학습된 모델을 쓰기보다 직접 갖고 있는 데이터를 학습시켜서 좀 더 좋은 모델을 만들어서 썼다고 한다. 이 모델이 성능이 좋았던게 데이터셋 퀄리티에 큰 영향을 미친 것 같다. ----------------- multiview image가 입력이기 때문에 각각 visible mask와 unwrapped texture가 N개 발생하는데 이걸 자연스럽게 이어붙이는건 특별한 것 없이 color tone matching만 해줬다. (mesh가 엄청 정확하단 소리) |
  |
mesh가 아무리 정확하더라고 입 안 공간, 콧구멍 같이 안으로 뚫린 공간의 경우 실패하기 마련이다. 이걸 풀려고 상용 소프트웨어도 써봤지만 결국 안돼서 콧구멍과 입은 그냥 template texture로 교체했다고 한다. 더불어 머리나 귀 같이 없는 부분도 template mesh texture로 교체 (그래서 데이터셋 홈페이지에 가면 모두 대머리인 것)  결과적으로 7만개 중 54165개 변환에 성공했다고 한다. 손으로 걸러내는 작업으로 최종 필터링을 했기 때문에 퀄리티가 꽤 좋음. |
 |
 |
 |
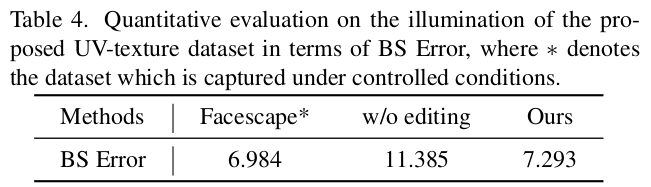 table 2의 점수는 arcface feature로 봤을 때 각 UV map이 얼마나 구분력 있게 생성됐는지를 본 것. FFHQ와 비슷할 수록 FFHQ 다양성이 그대로 전이됐다고 볼 수 있음 |
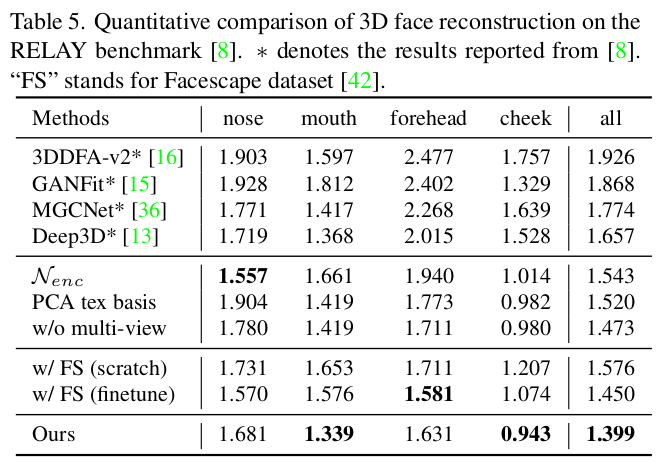 |
 |
 |
 |
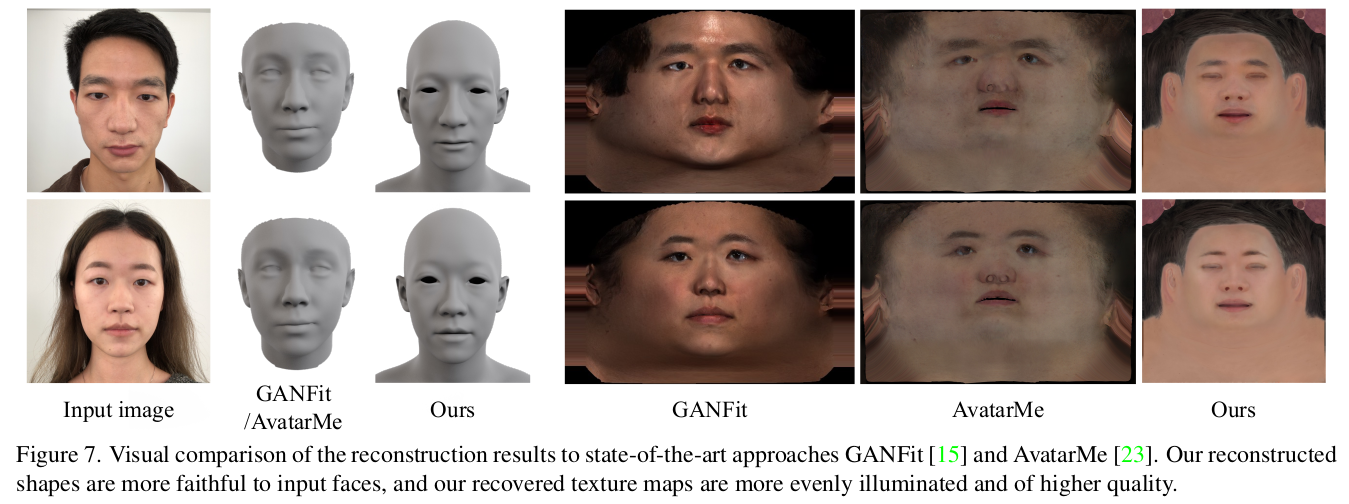  |
반응형
'Paper > Human' 카테고리의 다른 글
| Topo4D: Topology-Preserving Gaussian Splatting for High-Fidelity 4D Head Capture (0) | 2024.12.26 |
|---|---|
| NICP: Neural ICP for 3D Human Registration at Scale (0) | 2024.12.23 |
| Pixel Codec Avatars (0) | 2024.12.03 |
| Cross-view and Cross-pose Completion for 3D Human Understanding (0) | 2024.11.14 |
| 3D Face Tracking from 2D Video through Iterative Dense UV to Image Flow (0) | 2024.10.30 |