반응형
내 맘대로 Introduction
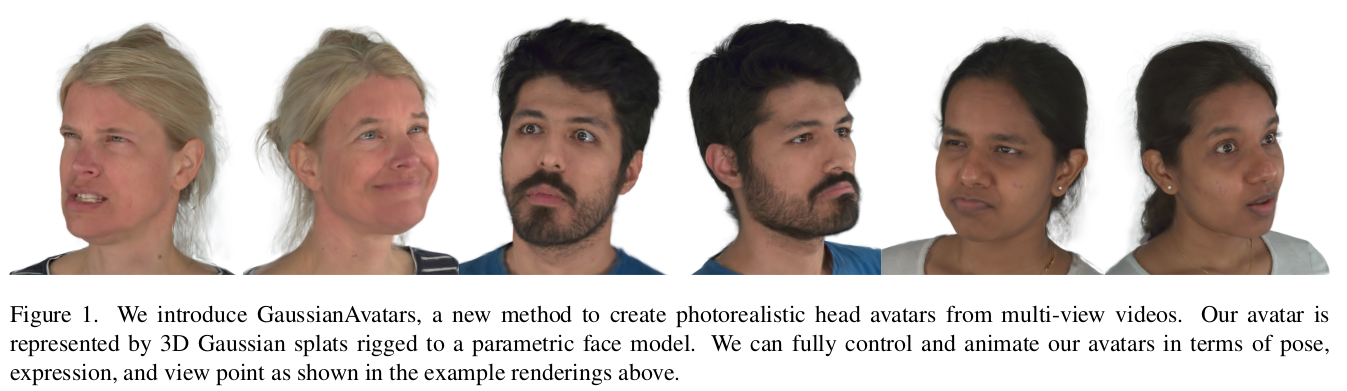
Multiview video 입력을 받아 FLAME 연계 3D Gaussian spaltting 학습하는 논문. 조금 나이브한 부분이 초기화할 때만 3D FLAME face <-> 3D Gaussian 간의 binding을 하고 densification, pruning할 때는 딱히 face 위에 있도록 강제한다는게 없다. regularization term으로만 face와 거리가 가깝게 유도할 뿐이다. 따라서 명시적으로 mesh와 align을 강제하지 않기 때문에 deformation 시 약점을 보일 것 같다.
정말 간단함.
메모
 |
|
  |
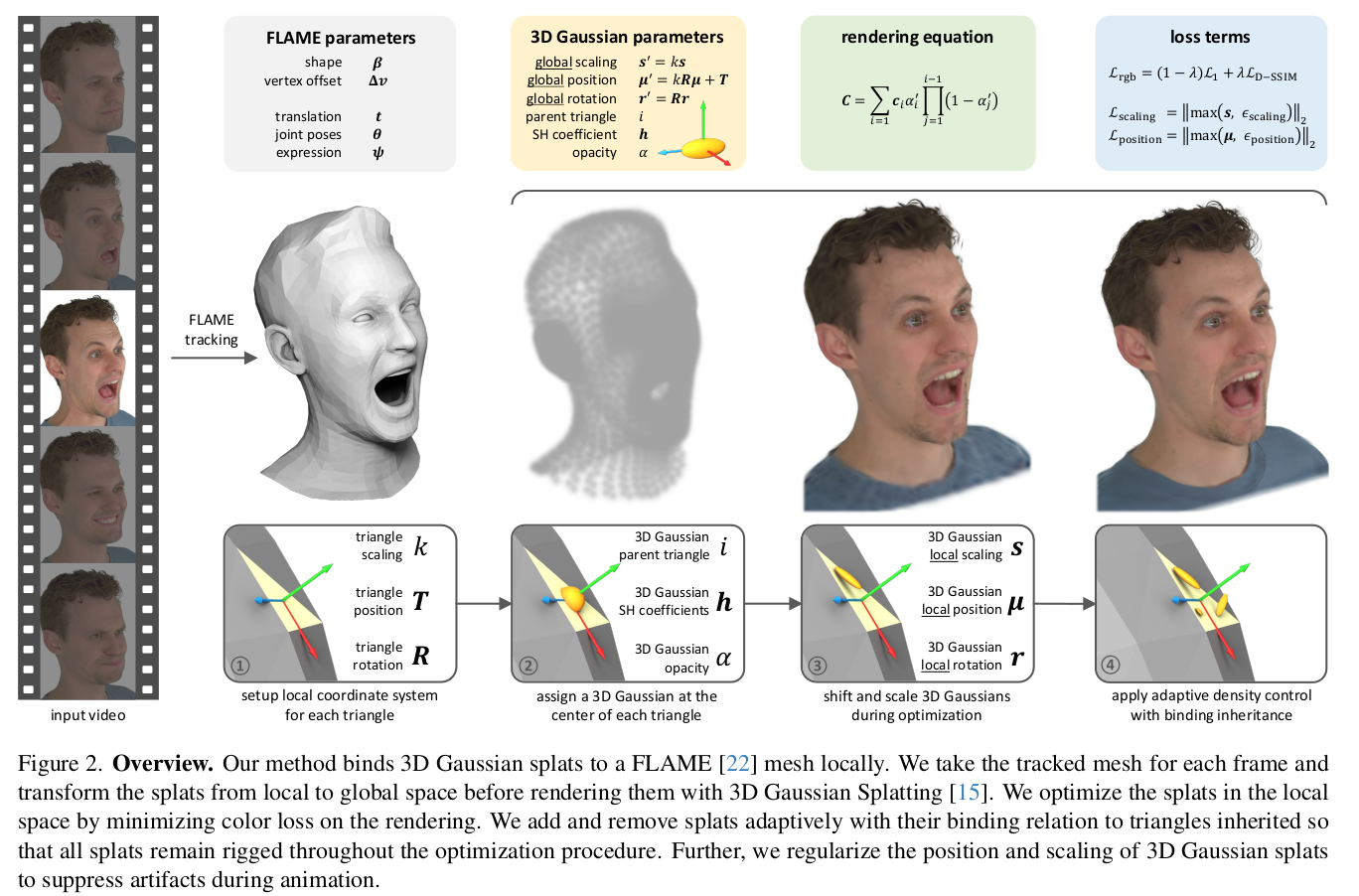
1) multivew video 각 frame마다 FLAME을 fitting 함 2) FLAME vertex마다 face 중심에 3DGS 생성 (normal을 이용한 회전각 초기화) 3) 3DGS 적용 (densification 시 face 내에서 복사, pruning 시 vanilla 3DGS랑 동일하지만 face 당 최소 1개는 남기는 방식) 4) 3DGS parameter들을 face 사이즈 대비 상대값으로 모델링해서 face 사이즈 비례 gradient가 기능하도록 함. |
 |
3D GS 의 파라미터는 다 local space에서 정의됨. 다시 말해 face 좌표계 대비 relative rotation, relative scale을 가짐. face를 구성하는 edge 길이의 평균 k값을 기준값으로 활용함. 이렇게 구성하면 실제 gradient가 1/k로 scale되는 구조이므로 face가 작을 수록 업데이트가 약하고, face가 클수록 업데이트가 강하다. |
  |
3DGS의 densification 시, 같은 face 내에서 split/clone 하는 방식. pruning은 원래 방식 그대로 주기적 opacity 초기화함. 다만 face 내 3dgs가 하나도 없을 경우에는 pruning하지 않음. |
 |
학습 loss 또한 rendering loss, l1 + SSIM 그대로임. 다만 3DGS 초기화/densification 시에만 위치를 face 내부로 고정해줄 뿐 최적화 과정에서는 자유롭게 움직일 수 있으므로 위 loss만 사용할 경우 3DGS가 face dependency가 너무 없어짐 -> deformation 시 artifact 증가 -------------- position loss 각 3DGS 마다 bounded face 크기를 기준으로 봤을 때 너무 face와 멀어지지 않도록 강제함. eps_position = 1 이므로 대충 face를 감싸는 sphere 안에서 벗어나진 않도록 강제하는 것 과 비슷함. |
  |
또한 너무 face 내에 큰 3DGS가 포진해 있으면 성능이 안좋다. 따라서 특정 크기 이하로 맞춰주기 위해서 역시 face 크기 대비 비율로 상한선을 맞춰준다. 대충 face 크기의 0.6배를 1개의 gs가 넘지 않도록. |
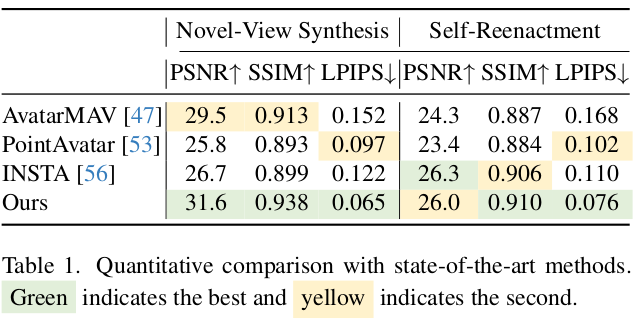 수치를 믿기엔 음.. 데이터셋 depedent가 클 듯. |
 |
  |
|
 |
|
 |
 |
반응형