반응형
내 맘대로 Introduction

이 논문은 CVPR 2023에서 무려 best paper를 받은 google 논문이다. 한마디로 요약하면, 학습 완료된 text-to-image generation model을 fine-tuning하는 방법을 소개한다. 예를 들어, 위 사진처럼 내 웰시코기 애완견 이미지를 생성하는 모델로 fine tuning하고 싶을 때, 입력 이미지 3~5 장 정도 넣어 학습하는 방법이다. LoRA와 더불어 fine tuning 정석 기법 중 하나로 여겨지고 있다.
핵심 내용은 unique identifier를 넣어서 tuning 대상이 어떤 것인지 명확히 지정하는 방법, 그 와중에 다른 대상에 대한 생성 결과는 원래대로 유지되도록 하는 방법 2가지다.
메모하며 읽기
 |
단순히 새로운 few shot 데이터로 학습을 짧게 다시 하는 방법을 생각할 수 있는데 이 방법은 효과적이지 않다. few shot으로는 output domain을 충분하게 형성할 수 없고, language와 vision이 합쳐진 embedding space를 사용하기 때문에 학습하더라도 language space의 영향이 있어 이미지만 identity가 유지되되도록 하기 어렵다. 그림2와 같이 tuning을 하면 그럴 듯 하긴 하지만 디테일을 눈여겨 보면 identity가 유지되지않는 것을 볼 수 있다. |
 |
text-to-image model은 image-text pair로 학습되지만, fine tuning은 이미지만 3~5장 있으면 되도록 설계했다. 1) unique idenfier를 활용해서 identity가 유지되도록 학습하는 방법 2) tuning 대상이 아닐 경우, fine tuning 전 모델과 같은 결과를 유지하도록 강제하는 loss 를 추가한 점이 핵심 아이디어다. |
 |
text-to-image model recap 부분이다. 요약하면, Stable diffusion, Imagegen 처럼 latent space diffusion model이고 text embedding이 condition으로 제공되는 형태를 알고 있어야 된다. |
  |
방법론을 설명하기 전에 고찰을 먼저 함. 기존 generation model fine tuning같은 경우, overfitting이나 mode-collapse 문제가 심했다고 함. 항상 같은 결과 나와버리는 현상. 그런데 diffusion model 같은 경우, 그런 현상이 없었고 디자인만 잘하면 적은 데이터로 few shot tuning하는 것이 가능했다고 함. 심지어 웬만한 다른 생성 결과들은 유지하는 상태로. |
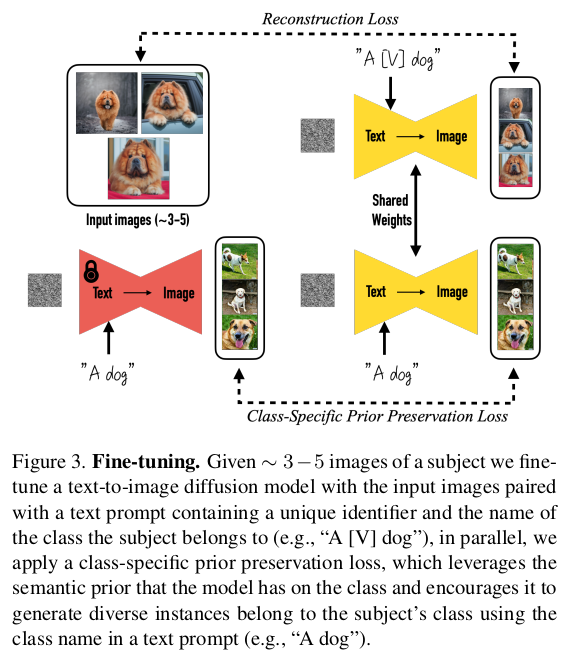 |
전체 파이프라인 그림은 왼쪽과 같음. tuning 대상을 네트워크가 알아차릴 수 있도록 [V] unique identifier를 추가한 text로 condition을 가하면서 reconstruction loss를 가함. 이 때 unique identifier를 알파벳 3~4개 구성의 사람이 봤을 땐 아무 의미없는 조합의 단어를 사용했고, text는 a [V] [class noun] 조합으로 간단하게 제한했다. 동시에 다른 대상은 복원 결과가 유지되도록, tuning 전 모델을 결과와 같도록 prior preservation loss를 가함 |
 |
tuning 대상임을 지정해주는 text를 조합을 고민하다가, 가장 간단하게 대상의 class noun 앞에 identifier만 붙이는 형태로 결정했다. class noun은 이미 학습 완료된 languange-vision space에서 시작점을 잡아주는 역할, identifier는 새로운 대상이므로 새로 학습해야 된다고 알려주는 역할을 하는 token이라고 보면 될 것 같다. 예시는 a [shs] dog 과 같다. |
  |
unique identifier는 어떻게 결정했는가? 1) 원래는 "unique", "special"처럼 사람 눈에 "특정" 대상이라는 의미 단어를 token으로 썼다고 하는데, 이러면 기존 모델이 이미 그런 단어들에 대한 space를 구축해두었기 때문에 모델에게 혼란을 야기해서 성능 저하로 이어졌다고 한다. 2) 무작위로 아무 의미없는 알파벳 조합으로 단어를 만들어서 사용하는 방식도 해보았는데 결국은 1)과 비슷한 성능이었다고 한다. 그래서 마지막으로 시도한 방법이 모델 학습 시 사용했던 vocabulary 중에서 선별해서 사용했다. rare token이라고 부르는데, vocabulary에 존재하는 token 중 de-tokenize했을 때 3~4 음절인 단어들을 그냥 rare token으로 지정하고 썼다. (방법은 사실 다양할 수 있을 것 같은데 Imagen, T5-XXL으로 실제 구현한 방식을 읽어보면 그냥 랜덤으로 가져왔다.) 결과적으로 a [shs] dog, a [tms] dog 과 같이 사람이 읽어선 아무런 tuning 대상과 연관 없는 단어가 붙게 되었다. ------------- 결국 실험적으로 방법을 결정한 것이다. |
  |
학습이 마냥 쉽진 않았을 것이다. 1) language model만을 다룰 때 language drift라고, 대형 모델을 작은 데이터셋에 튜닝할 때 원래 language 이해력이 망가지는 문제가 있는데 비슷한 현상이 language-vision model 에서도 발생했다고 한다. 2) 또, 결과물의 자유도가 좀 낮아지는 현상도 있었다고 한다. text에 따라 엄청난 자유도의 이미지가 나와야 하는데 비슷비슷하게 현상되는 느낌. 특히 학습 시간이 길어지면 심해짐 (overfitting, mode-collapse) 이 두 가지 문제를 해결하는 방식으로 tuning 전 모델과 유사하도록 강제하는 loss를 사용했다. unique identifier가 들어가지 않은 문장에 대해선, tuning 전후가 같은 결과를 내뱉도록 l2 loss를 걸어준 것이다. |
 |
 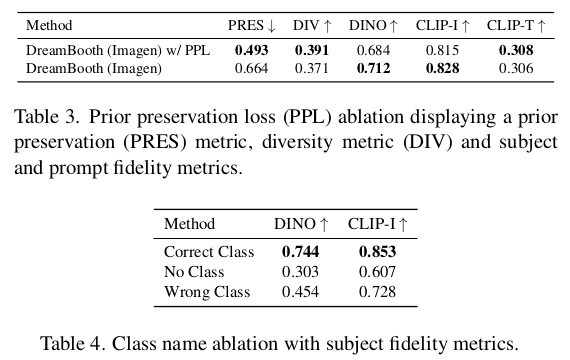 |
 |
| 데이터셋도 따로 제공을 해주었는데, 위 데이터셋을 활용해서 기존 Imagen을 튜닝하면 아래 같은 결과들이 나온다. |
 |
|
 |
 |
 |
  |
  |
반응형