반응형
내 맘대로 Introduction

더하기 더하기 더하기 논문. 3d reconstruction 더하기 + texturemap inpainting 더하기 + lighting condition estimation 더하기. 결과적으로 이미지가 들어갔을 때 해당하는 3D MESH + diffuse, specular, albedo, lighting 등등 렌더링에 필요한 모든 파라미터가 추정된다. 듣기만 해도 어마어마하게 데이터가 필요해 보이는데 역시 890명의 light stage dataset를 자체구축해서 사용했다.
더불어서 렌더링에 필요한 모든 요소가 결과물로 나오기 때문에 differentiable rendering을 통해 photometric loss를 걸어줄 수 있기 때문에 in-the-wild 이미지로 간접 학습을 할수도 있다. 그래서 semi-supervised라는 이름이 붙음. 확실히 generalization에 도움이 될 듯.
개인적으로 데이터가 강하게 확보된 상황에서 추정한 논문이라서 흥미가 가진 않는다.
메모
 |
|
  |
1) 3D mesh parameter regression 2) texture warping + inpainting 3) light normalization (데이터로 빛을 없애는 네트워크를 따로 학습해둠) 4) texture map으로부터 렌더링에 필요한 각종 intrinsic 추정 (이것도 네트워크 따로 학습) 결과적으로 단계 별로 네트워크를 여러개 따로 학습해서 조합한 것. |
  |
 첫 시작인 3D MESH paramter 추정하는 것. shape, expression, reflectance, light, camera 총 5개 파라미터를 추정하는 regressor를 만들어두는 것이 목적. 데이터가 이미 있으므로, 해당 데이터를 사용해서 학습시킴. 그리고 렌더링이 가능하기 때문에 photometric loss로 일반 이미지도 추가해서 학습 보조. ---------- 마이너하게 그냥 mesh basis + coefficient 추정으로 안하고, VAE 형식으로 latent화 해둔 3DMM을 사용함. 다른 이유는 없고 이게 좀 더 성능이 좋았다고 함. |
 label이 있는 이미지건, 없는 이미지건 둘 다 적용되는 공통의 loss는 수식(1)과 같이 photometric loss + landmark loss + regularization regularization은 결과 mesh가 매끄럽게 laplacian이 들어가고 나머지는 파라미터 크기를 0으로 억제하는 것 |
 GT가 있는 데이터는 직접 Mesh Vertex가 같도록 , normal이 같도록 걸어줌 -> 이게 가장 강력한 loss 데이터가 모델이 890개니까 이미지는 수만장일 것. |
 |
texture inpainting은 기본적으로 mirroring 한 뒤, 데이터로 image to image tranlsation network 학습해서 사용함. 별도의 모델인 셈. |
  |
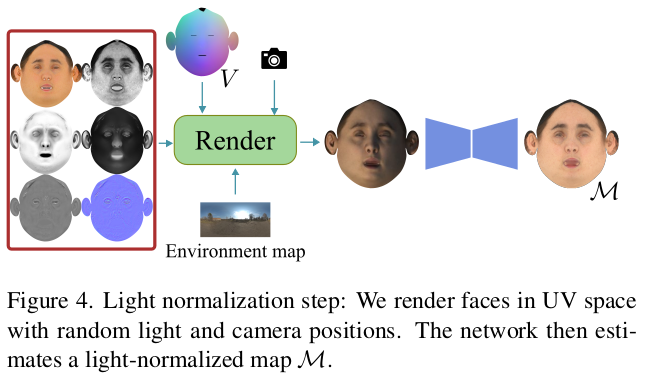 빛 제거 역시 기존에 갖고 있는 데이터를 무작위로 렌더링한 뒤에 렌더링 결과 -> 렌더링 전으로 돌리는 네트워크를 학습시켜둬서 사용. |
 |
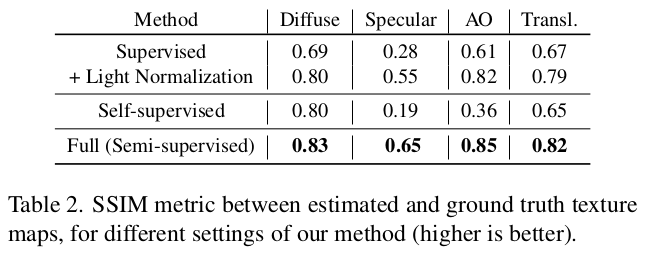
 마지막 최종은 texture map으로 하여금 해당 얼굴의 diffuse, specular, ambient occlusion, translucency를 계산하는 것. 디테일한 렌더링까지 나아가기 위해 필요한 것들이 추가된 셈. 역시 데이터가 있기 때문에 각 대상마다 네트워크를 따로 두고 묶어서 한 번에 학습 (렌더링은 한번에 해야하니까) |
  |
normal을 뽑아내는 것이 조금 더 디테일이 들어가야 모공이나 주름도 복원할 수 있는데 이는 patch 단위로 쪼갠 뒤, 각각 PCA로 나누고 PCA로 복원한 이미지가 기본값으로 들어가 한 번 더 refine되는 구조를 차용했다고 함.->사실 데이터가 주름, 모공 수준으로 있다는 얘기가 더 중요한 것 같다. |
 |
데이터가 있으므로 강력하게 supervision 걸어주면서 학습. uv domain이기 때문에 일반 이미지는 쓸 수 없다. 여기부터는. |
  |
  여기는 결과물로 어떻게 shading했는지 적어둔 내용이라 그냥 패스. |
 |
  |
 |
|
 |
 |
반응형
'Paper > Human' 카테고리의 다른 글
| 3D Face Modeling via Weakly-supervised Disentanglement Network joint Identity-consistency Prior (0) | 2024.10.18 |
|---|---|
| 3D Face Modeling from Diverse Raw Scan Data (0) | 2024.10.18 |
| Face Editing Using Part-Based Optimization of the Latent Space (0) | 2024.10.15 |
| Generalizable and Animatable Gaussian Head Avatar (a.k.a GAGAvatar) (0) | 2024.10.14 |
| Sapiens: Foundation for Human Vision Models (2) | 2024.08.26 |