반응형
내 맘대로 Introduction

오랜만에 읽고 마음에 쏙 든 논문. 3D Mesh VAE를 학습한 논문인데 아이디어는 별 것 아닌 것처럼 보이지만 고개를 끄덕이게 되는 simple yet effective 내용.
3D mesh (topology는 정해져있음)를 VAE latent로 encoding하는 과정에서 part 별로 latent를 따로 뽑고, part latent끼리를 영향을 주지 않도록 (다른 part vertex 위치 변화에 간섭하지 않도록) 학습을 해두는 것이 핵심이다.
이렇게 학습을 하면 나중에 vertex를 손으로 수정함 -> 해당 파트 latent만 inverse optimization으로 찾아냄 -> decoding -> 수정된 vertex 위치를 갖는 mesh가 나오는 활용이 가능해진다.
editing이 가능하도록 만들고 싶다는 목적을 간단하고도 납득가는, 증명된 방법을 조합해서 만들어낸게 굉장히 깔끔해보인다.
메모
 |
  그리곤 각 segment vertex encoder를 7개 따로 두어 VAE를 만든다. 단 decoder는 하나. (7개 encoded latent를 입력으로 받음) 이렇게 하는 이유는 editing이 얼굴 일부에서 일어나면, 나머지는 고정되어 있어야 하기 때문에 구분력을 주기 위한 초석. |
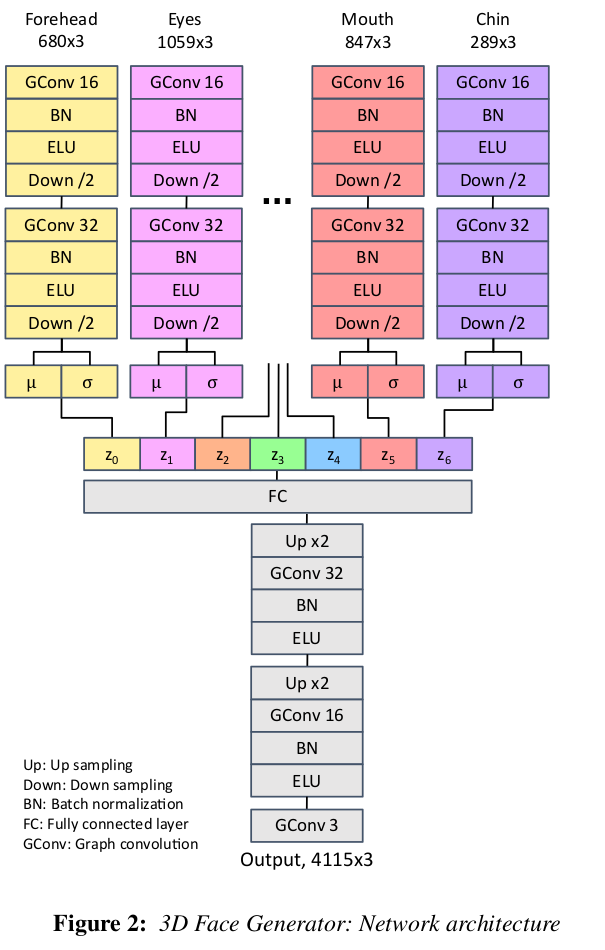 네트워크 구조에 대한 정말 정확한 설명. 그냥 깔끔... mesh 상에 convolution을 사용해야 하기 때문에 gnn 분야에서 fast spectral convolution을 가져와서 사용했다. -> 정확하 내용을 이해할 필요는 없음. -> mesh vertex 상의 convolution 사용했다는 점만 기억. |
  |
  |
loss 1 : 수식 (4) - VAE니까 입력-출력이 같아야 함. - 가장 기본이 되는 loss loss 2 : 수식 (5) - VAE 고유 loss - latent가 gaussian 분포를 따르도록 유도 loss 3 : 수식 (6) - part latent 분리에 핵심이 되는 내용. - 7개의 latent 중 일부만 random noise로 교체 - decoder(original version) vs decoder(random noise version) - 위 두 결과를 비교했을 때 교체한 일부 part vertex를 제외한 나머지는 그대로 유지 되어야 한다는 loss  레시피까지 깔끔하게 적어줬다. |
 |
|
  |
face editing으로 어떻게 활용하느냐? latent 를 직접 수정하는건 직관적이지 않다. 가장 직관적인 방법은 사람이 vertex position을 움직이는 것. -> vertex position을 움직이면 해당 위치로 이동하도록하는 part latent를 inverse optimization을 찾아내서 사용함. -> 이때 변형한 vertex가 있는 part 값만 최적화로 찾아냄 수식(7)을 보면 아주 직관적.. 변형한 N개의 vertex는 새위치로 이동시키면서 + 나머지 part vertex는 그대로 유지하도록 하는 part latent를 찾아내는 것.   Adam으로 lr 크게 최적화해서 빠르게 찾아내도 잘 찾는다고 함. |
 |
892개 자체 mesh 활용해서 메인 모델 학습했고 작은 데이터로도 잘 동작한다는 것을 보여주기 위해서 facewarehouse에 대해서 테스트했다고 함. |
 |
|
 |
 |
 |
 |
 |
 |
 |
반응형
'Paper > Human' 카테고리의 다른 글
| 3D Face Modeling from Diverse Raw Scan Data (0) | 2024.10.18 |
|---|---|
| MoSAR: Monocular Semi-Supervised Model for Avatar Reconstruction using Differentiable Shading (0) | 2024.10.15 |
| Generalizable and Animatable Gaussian Head Avatar (a.k.a GAGAvatar) (0) | 2024.10.14 |
| Sapiens: Foundation for Human Vision Models (2) | 2024.08.26 |
| iHuman: Instant Animatable Digital Humans From Monocular Videos (0) | 2024.08.20 |